


What is Data Cleansing – From Chaos to Clarity
In today’s data-driven world, the phrase “garbage in, garbage out” holds more truth than ever. The insights and analyses you derive from your data are only as reliable as the data itself.
Inaccurate or inconsistent data can lead to flawed conclusions, misguided decisions, and missed opportunities. And as the volume of available data continues to surge, so does the potential for errors and inconsistencies within that data.
This is where data cleansing steps in as an essential practice to elevate the quality of data and, consequently, the decision-making processes.
What is Data Cleansing?
Data cleansing involves the meticulous process of detecting and rectifying corrupt, imprecise, or insignificant data. This pivotal phase in data processing plays a crucial role in enhancing the uniformity, dependability, and worth of your organization’s data assets.
Typical inaccuracies found in data encompass absent values, mislaid entries, and typographical blunders. Depending on the scenario, data cleansing may necessitate the addition or correction of specific values, or alternatively, the elimination of certain values altogether.
Data that harbors errors and disparities is commonly referred to as “dirty data,” and its implications are tangible. Studies indicate that a mere 3% of data conforms to fundamental quality standards, while the ramifications of unclean data translate to a staggering cost of over $3 trillion annually for U.S. companies.
Why is Data Cleansing Important?
The significance of data cleansing lies in its ability to guarantee the attainment of top-tier data quality. This practice doesn’t merely stave off errors but also acts as a shield against potential sources of annoyance for both customers and employees.
It elevates productivity levels, enhances the precision of data analysis, and cultivates a more informed decision-making environment. This rationale becomes evident when considering the repercussions of neglecting data cleaning.
A dataset left uncleansed is prone to inaccuracies, disarray, and incompleteness. As a consequence, any attempts at data analysis become encumbered, resulting in outcomes that are challenging to decipher, less coherent, and diminished in accuracy.
The decisions formulated based on such analyses subsequently suffer the same setbacks. Having established the essence of data cleansing and its importance, the following sections delve into types, benefits, specific data cleaning steps and techniques to provide a comprehensive understanding of this essential process.
Types of Data Cleansing
There exist two primary categories of data cleansing:
- Traditional
- Big Data Cleansing
Traditional Data Cleansing
This approach proves insufficient when handling massive volumes of data. In earlier times, when organizations weren’t generating data records by the thousands or millions, these methods held their utility.
Within the realm of cleansing smaller data sources, two principal strategies are at play. The first method involves an interactive system that amalgamates error detection and data transformation, utilizing an interface resembling that of a spreadsheet.
Users can establish custom domains and then define algorithms to enforce domain rules. This demands meticulous and precise manual interventions.
Explore the Possibilities of Modern Data Cleansing Solutions that Transcend the Limitations of Traditional Methods
While there are other methods, they largely center on eliminating duplicates. This framework follows a systematic process of:
- Pre-processing: Detection and removal of data anomalies.
- Processing: Application of rules, like identifying duplicates.
- Validation: Human oversight of processing outcomes.
While these strategies may have sufficed in the past, they are labor-intensive and fail to ensure data quality to the extent that modern data cleansing tools do.
Data Cleansing for Big Data
Cleansing big data presents the most significant challenge across numerous industries. With the data volume already colossal, unless proactive measures are taken, this challenge will only magnify.
Various potential approaches exist to tackle this issue, demanding complete automation devoid of human intervention to achieve effectiveness and efficiency.
Specialized Data Cleansing Tools
These tools often cater to specific domains, primarily dealing with name and address data or focusing on duplicate removal. Numerous commercial tools specialize in cleansing such data.
They extract data, segment it into individual elements like phone numbers, addresses, and names, validate address details and zip codes, and subsequently match the data. Once records are aligned, they merge into a unified entity.
Extract Transform and Load (ETL) Tools
Many organizational tools support the ETS process for data warehouses. In the “transform” step, which is the cleansing phase, these tools remove inconsistencies, errors, and detect missing information. The diversity of cleansing tools within the transform step depends on the software used.
These methods further branch into distinct error detection approaches:
- Statistical Method for Error Detection: This technique involves spotting outlier records by employing mathematical principles like averages, means, standard deviations, and ranges. When records deviate significantly from anticipated norms or fail to conform to existing data patterns, they are identified as outliers. While this approach might yield false positives, it’s quick and straightforward, often complementing other methods.
- Pattern-Based: Here, outlier fields that don’t conform to established data patterns are identified. Techniques like partitioning, clustering, and classifying are employed to spot patterns that are prevalent among the majority of records.
- Association Rules: Utilizing “if-then” statements, association rules indicate the probability of relationships between records. Data that doesn’t adhere to these rules is regarded as outliers.
In essence, the data cleansing landscape encompasses both traditional methods, suitable for smaller datasets, and sophisticated techniques tailored to address the challenges posed by big data.
Benefits of Data Cleansing
The advantages of data cleansing extend across various facets of an organization’s operations, data-driven strategies, and overall success. Here are the key benefits that data cleansing brings:
Enhanced Data Accuracy
Data cleansing rectifies errors, inconsistencies, and inaccuracies within datasets, ensuring that the information you work with is dependable and trustworthy.
Reliable Decision-Making
Clean data forms the basis for making well-informed decisions. It leads to more accurate insights, reducing the likelihood of misguided choices based on faulty information.
Improved Customer Relationships
Clean data enables personalized interactions with customers, fostering positive experiences and stronger relationships due to accurate information about their preferences and needs.
Operational Efficiency
Clean data streamlines processes by minimizing the need for error correction and troubleshooting. This improves overall efficiency and productivity across various functions.
Ready to Experience the Transformative Power of Data Cleansing?
Effective Analytics
High-quality data is essential for accurate data analysis and meaningful insights. Clean data ensures that your analytical models produce reliable and actionable results.
Cost Savings
By preventing errors and inaccuracies, data cleansing prevents costly mistakes, such as targeting the wrong audience in marketing campaigns or investing in erroneous market trends.
Compliance and Security
Data cleansing ensures compliance with data protection regulations by maintaining accurate and up-to-date records. It also contributes to data security by minimizing vulnerabilities.
Optimized Marketing Campaigns
Clean data enables precise audience segmentation and targeting, leading to more successful and efficient marketing campaigns.
Minimized Redundancy
Data cleansing identifies and eliminates duplicate entries, reducing redundancy and optimizing storage resources.
Strategic Insights
Accurate data allows organizations to uncover trends, patterns, and opportunities that might otherwise remain hidden in a sea of inaccuracies.
Effective Cross-Functional Collaboration
Clean data fosters better communication and collaboration among teams, as everyone is working with the same accurate information.
Higher Customer Satisfaction
Clean data leads to accurate order fulfillment, timely customer service, and reduced errors, contributing to a higher level of customer satisfaction.
Long-Term Data Value
Maintaining data quality through cleansing ensures that historical data remains valuable and usable for future analysis and decision-making.
Competitive Advantage
Organizations that prioritize data quality through cleansing gain a competitive edge by making well-grounded decisions and providing superior customer experiences.
Components of Clean Data
Clean data is characterized by several essential components that collectively contribute to its accuracy, reliability, and usability. Here are the key components of clean data:
Accuracy
Clean data is free from errors, inaccuracies, and inconsistencies. It provides a faithful representation of the real-world entities and attributes it aims to describe.
Completeness
Clean data contains all the necessary and relevant information without missing values or incomplete records. It ensures that no crucial details are omitted.
Consistency
Clean data adheres to standardized formats, units, and conventions. It maintains uniformity throughout the dataset, preventing variations that could lead to confusion or misinterpretation.
Validity
Clean data satisfies predefined validation rules and criteria. It meets the established constraints and business rules, reducing the presence of outliers or improbable values.
Reliability
Clean data can be trusted to accurately represent the information it stands for. It’s free from fabricated or manipulated values that could skew analyses or decisions.
Timeliness
Clean data is up-to-date and relevant for the intended purpose. It reflects the current state of affairs and is void of obsolete or outdated records.
Uniqueness
Clean data eliminates duplicate entries, ensuring that each entity or record appears only once within the dataset. This prevents overcounting and redundancy.
Standardization
Clean data adheres to a consistent structure, naming conventions, and units. It minimizes variations that could arise from different sources or entry methods.
Contextual Relevance
Clean data is contextually relevant to the objectives of analysis or decision-making. Irrelevant or extraneous information is removed to maintain focus.
Ready to Harness the Power of Pristine Data for Your Organization’s Success?
Data Integrity
Clean data is safeguarded against unauthorized modifications, ensuring that its quality and accuracy remain intact over time.
Auditability
Clean data is traceable, allowing for the tracking of changes and modifications. This is crucial for maintaining transparency and accountability.
Data Governance
Clean data is managed and maintained through established data governance practices, ensuring continuous quality and adherence to standards.
Usability
Clean data is easily accessible, understandable, and usable by various stakeholders within the organization. It supports effective decision-making and analysis.
Incorporating these components into data cleaning processes ensures that the resulting data is of high quality and can be relied upon for accurate insights and informed decisions.

Data Cleansing Challenges
Data cleansing presents various challenges that organizations must navigate. Chief among these is the significant time investment it demands due to the multitude of issues that arise in numerous datasets, along with the intricate nature of identifying the origins of certain errors.
Alongside this, several other common challenges come to the forefront, including:
Resolving Missing Data Values
Determining how to address missing data values effectively without impinging on the accuracy of analytics applications poses a substantial challenge.
Tackling Inconsistent Data
Rectifying inconsistent data scattered across systems managed by distinct business units requires intricate coordination and alignment.
Addressing Diverse Data Quality in Big Data Systems
Overcoming data quality challenges in expansive big data systems housing a blend of structured, semi-structured, and unstructured data introduces complexities in the cleansing process.
Resource Allocation and Organizational Backing
Garnering sufficient resources and garnering comprehensive support from the organization is essential for executing successful data cleansing initiatives.
Navigating Data Silos
Confronting the complexities introduced by data silos, which hinder the seamless flow of data and exacerbate the intricacies of the data cleansing process, presents its own set of obstacles.
These formidable challenges accompany the journey of data cleansing. However, understanding and strategizing around these issues can empower organizations to undertake effective data cleansing processes that lead to improved data quality and better decision-making outcomes.
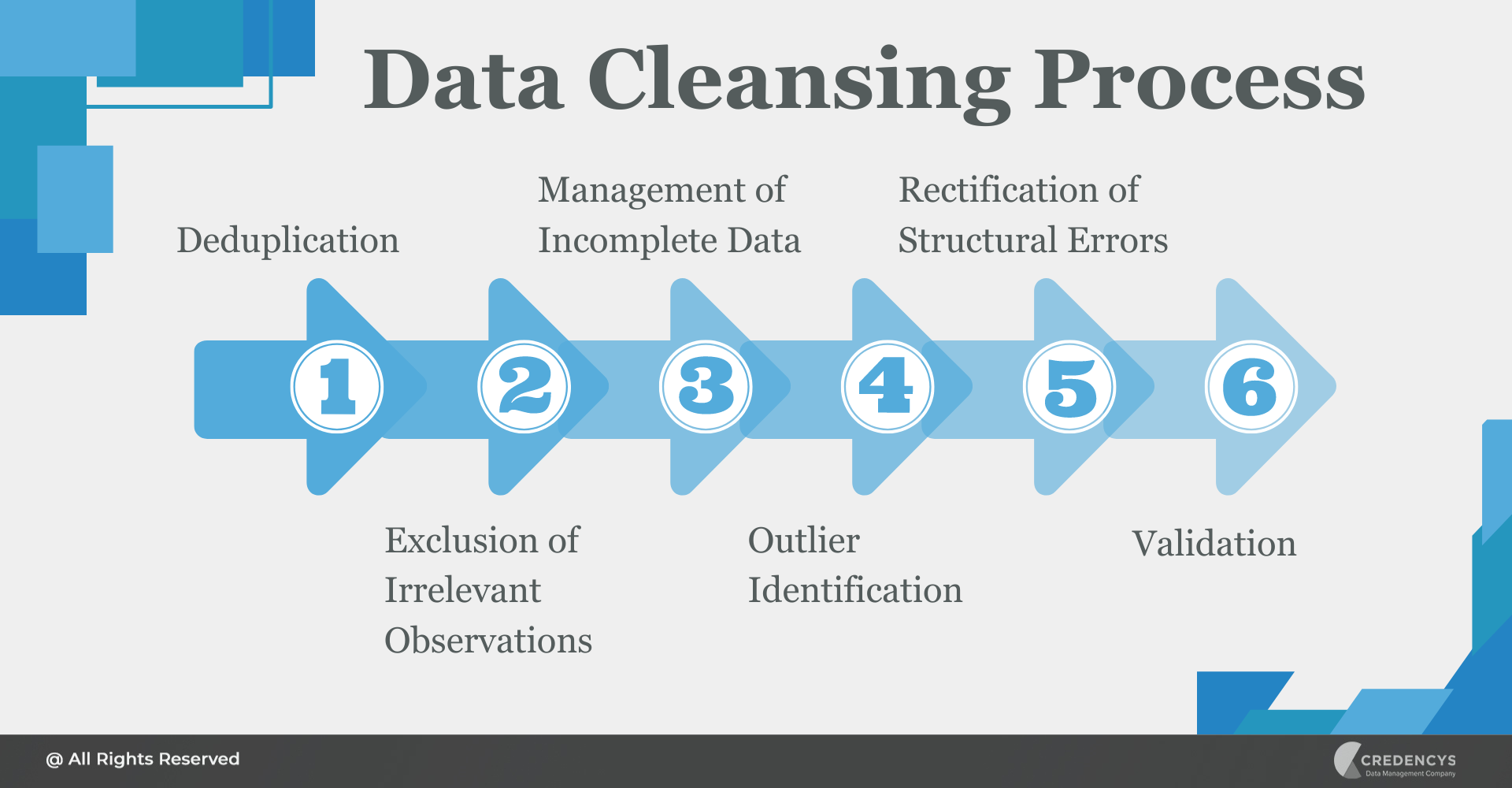
Data Cleansing Process
Data cleansing constitutes a vital phase within any analytical procedure, often encompassing a sequence of six distinctive stages:
Deduplication – Eliminating Duplicate Entries
Duplicates frequently emerge when amalgamating data from various origins like spreadsheets, websites, and databases, or when a customer interacts with a company through multiple channels or submits redundant forms. The repetition of such data engenders the consumption of server resources and processing power, leading to larger files and less efficient analysis.
The deduplication process tailors its rules based on an organization’s intended outcome. For instance, if a customer provides varying email addresses across different sections of a website, a cautious approach will discard data rows only when every field is an exact match.
Exclusion of Irrelevant Observations – Removing Impertinent Data Points
Data points that hold no relevance to the specific problem being addressed can impede processing speed. Excluding these irrelevant observations doesn’t entail erasing them from the source; rather, it omits them from the ongoing analysis.
Take the First Step Towards Data-Driven Success With our Cutting-Edge Data Cleansing Services
For instance, when scrutinizing campaigns from the previous year, data beyond that timeframe need not be included. However, it’s essential to recognize that even variables seemingly unnecessary might exhibit a correlation with the investigated outcome (e.g., a customer’s age potentially influencing the success of an email campaign).
Management of Incomplete Data – Addressing Incomplete Data
Data might exhibit missing values due to various factors like customers omitting certain information. Tackling this issue is pivotal for accurate analysis, as it forestalls bias and erroneous calculations.
Following the isolation and examination of incomplete values, which might manifest as “0,” “NA,” “none,” “null,” or “not applicable,” it’s essential to ascertain if these values are plausible or stem from absent information. While discarding incomplete data might be the simplest solution, the potential for bias arising from such action must be acknowledged.
Alternatives encompass substituting null values through statistical or conditional modeling, or annotating the missing data for transparency.
Outlier Identification – Detecting Outlying Data Points
Data points that significantly deviate from the rest of a dataset can distort the overall data representation. Visual or numerical techniques such as box plots, histograms, scatterplots, or z-scores aid in identifying these outliers.
When integrated into an automated process, these techniques facilitate prompt assumption testing and subsequent resolution of data anomalies with a higher degree of certainty. Once detected, the decision to include or exclude outliers hinges on their extremeness and the statistical methodologies employed in the analysis.
Rectification of Structural Errors – Addressing Inaccuracies in Structure
Rectifying errors and inconsistencies, encompassing typographical errors, capitalization inconsistencies, abbreviations, and formatting discrepancies, assumes paramount significance. Examining the data type for each column and ensuring entries are accurate and uniform involves standardizing fields and eliminating extraneous characters like additional whitespaces.
Validation – Ensuring Accuracy and Uniformity
Validation constitutes the process of verifying data for accuracy, completeness, consistency, and uniformity. Although inherent within an automated data cleansing process, it remains crucial to execute a sample run to confirm alignment.
This phase also provides an opportunity to document the tools and techniques utilized throughout the data cleansing process.
Closing Thoughts
In a landscape where data drives innovation, disruption, and growth, the steps outlined in this journey exemplify the synergy between human intelligence and cutting-edge technology. Data cleansing is not a mere technical chore but a strategic imperative that underpins business success.
It’s a commitment to accuracy, a pledge to transparency, and a dedication to ensuring that data tells a reliable story—one that guides decisions, builds trust, and shapes the future. As we conclude this exploration of data cleansing, let’s embrace the lessons learned and the methodologies unveiled.
Let’s harness the power of clean data to elevate our organizations, foster meaningful relationships with customers, and pioneer solutions that stand the test of time. With data cleansing as our compass, we embark on a path of discovery where every insight gleaned, and every decision made is fortified by the unwavering commitment to data quality.
Ready to Revolutionize Your Data and Drive Your Organization’s Success to New Heights?





Tags: