


What is Data Pipeline - An Ultimate Guide to Transforming Data Management
In the digital age, data has become the lifeblood of businesses across all industries. The ability to harness, analyze, and derive insights from data has become a crucial competitive advantage.
However, with the ever-expanding volume, variety, and velocity of data being generated, managing this wealth of information has become a daunting task for many organizations.
This is where data analysts and data engineers resort to data pipelining.
Data Pipeline – Definition
To address the challenges of data management, the use of a Data Pipeline – a dynamic and efficient mechanism that orchestrates the flow of data from diverse sources to target destinations is recommended. The Data Pipeline acts as a conduit, facilitating the movement, transformation, and processing of data in a systematic and automated manner.
Role of the Data Pipeline
The Data Pipeline plays a pivotal role in optimizing data management processes and streamlining the flow of information. Its key functions include:
Data Integration
Aggregating data from various sources, regardless of its format or location, into a unified and accessible environment.
Data Transformation
Applying data transformations and enrichment to ensure data consistency, quality, and relevance.
Data Movement
Seamlessly moving data between systems, databases, and applications, enabling real-time or batch data processing.
Data Governance
Implementing data governance policies to maintain data accuracy, security, and compliance throughout its journey.

In the world of data management, a Data Pipeline emerges as a powerful and indispensable tool that revolutionizes the way organizations handle their data. Understanding the essence of a Data Pipeline and its functionalities is crucial for businesses seeking to streamline their data flow and optimize their data management processes.
What is Data Pipeline?
At its core, a Data Pipeline can be envisioned as a series of interconnected stages through which data flows, undergoing transformation and processing along the way. It acts as a structured pathway that facilitates the movement of data from diverse sources to specified target destinations, ensuring data accessibility and availability for various use cases.
Just like a physical pipeline carries and channels liquids from one point to another, a Data Pipeline carries and directs data, making it an essential component of efficient data management.
Purpose of Data Pipeline
The primary purpose of a Data Pipeline lies in automating and orchestrating the complex process of data movement, transformation, and processing. By leveraging a Data Pipeline, organizations can:
Transform Data
Data may come in various formats and structures from multiple sources. A Data Pipeline allows organizations to apply data transformations, standardizations, and enrichments, ensuring data consistency and quality throughout its journey.
Process Data in Real-time or Batch
Depending on the nature of the data and business requirements, a Data Pipeline can process data in real-time, enabling immediate insights and actions, or in batches, optimizing the utilization of resources for larger datasets.
Move Data Seamlessly
Data can flow through a network of systems, applications, and databases. A Data Pipeline simplifies the movement of data, allowing smooth data transfer between these interconnected components.
Ready to Streamline Your Data Management and Unlock the True Potential of Your Data?
Enable Data Integration
In a modern data landscape, data resides in multiple sources and systems. A Data Pipeline integrates data from diverse sources, eliminating data silos and creating a unified view of information.

Key Components of a Data Pipeline
To comprehend the workings of a Data Pipeline, it is essential to grasp its key components, each playing a critical role in managing the flow of data:
Data Sources
Data Pipelines start with data sources, which can include databases, cloud storage, applications, APIs, log files, and more. These sources act as the origins of data that need to be collected and processed.
Data Transformations
The Data Pipeline includes mechanisms for data transformations, where data undergoes cleansing, enrichment, aggregation, and other manipulations to ensure its relevance and reliability.
Data Storage
During its journey, data might be stored temporarily or permanently at various points within the Data Pipeline. This storage can be in the form of databases, data lakes, data warehouses, or cloud storage.
Data Destinations
The Data Pipeline directs data towards specific destinations or target systems where it will be used for analysis, reporting, visualization, or other purposes.

Benefits of Implementing a Data Pipeline
In the realm of modern data management, the implementation of a Data Pipeline brings forth a myriad of advantages that revolutionize how businesses handle their data and make informed decisions. Let’s explore the transformative benefits of incorporating Data Pipelines into data management processes.
Advantages in Data Management and Decision-Making
Streamlined Data Flow
A Data Pipeline establishes an organized and structured pathway for data to flow seamlessly from source to destination. By automating data movement, businesses can efficiently manage data pipelines, reducing manual intervention and human errors.
Real-time Insights
With real-time data processing capabilities, Data Pipelines enable businesses to access and analyze up-to-date information. This empowers decision-makers to respond rapidly to changing trends, customer behaviors, and market conditions, fostering a competitive edge.
Enhanced Data Quality and Consistency
Data Pipelines enforce data transformations, cleansing, and validations, ensuring data quality and consistency across all stages. As a result, businesses can rely on accurate and reliable data for making critical decisions.
Efficient Resource Utilization
Data Pipelines optimize resource utilization by automating data processing tasks, thus freeing up human resources for more strategic and value-added activities.
Data Governance and Compliance
Implementing Data Pipelines facilitates the enforcement of data governance policies throughout the data journey. This ensures compliance with data regulations and fosters data security and privacy.
Enhanced Data Quality, Reliability, and Consistency
Data Pipelines play a pivotal role in enhancing data quality, reliability, and consistency through various mechanisms:
Data Validation
Data Pipelines validate incoming data against predefined rules, identifying and handling erroneous or inconsistent data to maintain data accuracy.
Data Enrichment
By enriching data with relevant information from external sources, Data Pipelines enhance the value and context of the data.
Error Handling
Data Pipelines are equipped to handle data processing errors effectively, ensuring data consistency and integrity.
Version Control
With Data Pipelines, organizations can maintain version control of data, enabling accurate historical analysis and comparison.
Ready to Elevate Your Data Quality and Drive Reliable Decision-Making with Enhanced Data Consistency?
Efficiency and Scalability from Automating Data Workflows
Data Pipelines introduce significant efficiency gains by automating repetitive data processing tasks:
Faster Data Processing
By automating data workflows, Data Pipelines enable faster data processing, resulting in timely insights and quicker decision-making.
Scalability
As data volumes grow, manual data processing becomes impractical. Data Pipelines offer scalability, accommodating larger datasets without compromising performance.
Resource Optimization
Automation reduces the need for human intervention in data processing, leading to cost savings and improved resource allocation.
Curating an Effective Data Pipeline Design
Designing a well-structured and efficient Data Pipeline is crucial for businesses to leverage the full potential of their data and drive meaningful insights. This section outlines the essential steps, best practices, and common challenges in curating a Data Pipeline design that aligns with the organization’s data requirements and objectives.
Define Data Requirements and Objectives
Begin by understanding the specific data requirements of your organization. Identify the sources of data, the desired data transformations, the frequency of data updates, and the target destinations.
Clearly define the objectives you aim to achieve through the Data Pipeline, whether it’s real-time data analysis, improved decision-making, or enhanced data integration.
Map the Data Flow
Create a detailed data flow diagram that illustrates the journey of data from its sources to its destination, including all intermediate steps and transformations. This mapping will provide a clear overview of the entire data pipeline process.
Data Transformation and Cleaning
Implement data transformation and cleaning processes at various stages of the pipeline to ensure data consistency, quality, and relevance. Use industry-standard data cleaning techniques to handle missing values, duplicates, and outliers.
Choose the Right Tools and Technologies
Select appropriate tools and technologies that align with your data pipeline requirements. Consider factors such as scalability, real-time processing capabilities, compatibility with existing systems, and ease of maintenance.
Data Governance and Security
Incorporate data governance practices into the design to maintain data security, privacy, and compliance with relevant regulations. Implement access controls and encryption methods to protect sensitive data.
Test and Monitor
Thoroughly test the Data Pipeline at each stage to identify and resolve any issues before deployment. Implement robust monitoring and logging mechanisms to track the performance and health of the Data Pipeline continuously.

Selecting Appropriate Data Pipeline Tools and Technologies
Data Integration Platforms
Consider using data integration platforms that offer features for connecting and transforming data from multiple sources. Popular choices include Apache NiFi, Talend, and Informatica.
Distributed Data Processing Frameworks
For handling large-scale data processing tasks, distributed data processing frameworks like Apache Spark and Apache Flink provide high performance and scalability.
Cloud Services
Cloud-based services such as AWS Data Pipeline, Azure Data Factory, and Google Cloud Dataflow offer fully managed data integration and processing capabilities, allowing organizations to focus on data insights rather than infrastructure management.
Message Brokers
Utilize message brokers like Apache Kafka or RabbitMQ to enable real-time data streaming and ensure data continuity in case of system failures.
Ready to Build a Powerful and Efficient Data Pipeline with the Right Tools and Technologies?
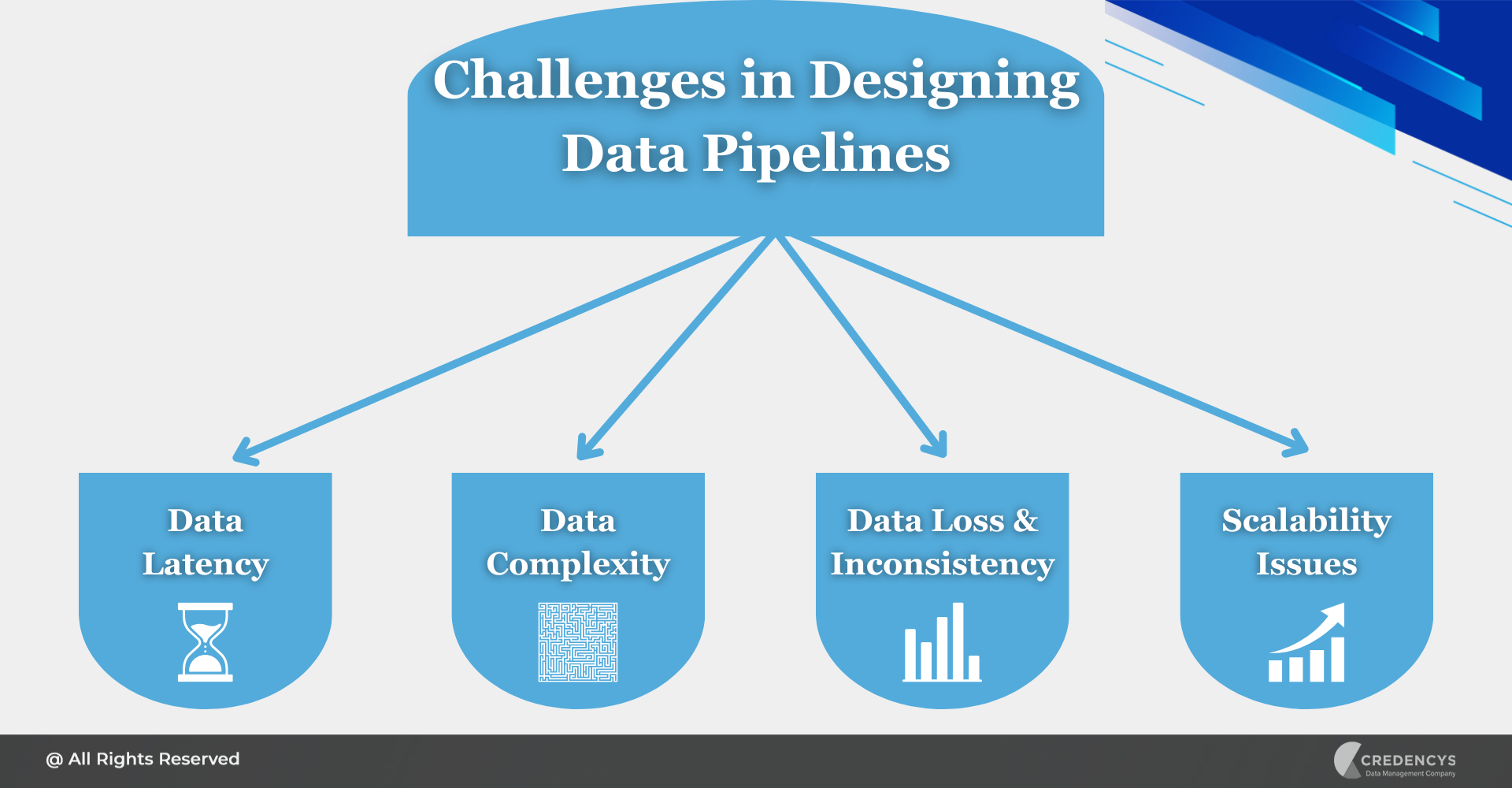
Addressing Common Challenges in Designing Data Pipelines
Data Latency
Minimize data latency by optimizing the data pipeline architecture and using appropriate tools for real-time data processing.
Data Complexity
Break down complex data transformations into smaller, manageable tasks to simplify the pipeline design and improve maintainability.
Data Loss and Inconsistency
Implement data checkpoints and error handling mechanisms to prevent data loss and maintain data consistency in case of failures.
Scalability Issues
Design the Data Pipeline with scalability in mind, leveraging distributed computing and cloud resources to handle increasing data volumes.
Data Security and Compliance in Data Pipelines
Data security and privacy considerations are of paramount importance in the design and implementation of Data Pipelines. As data continues to play a critical role in driving business decisions, safeguarding sensitive information and complying with data regulations have become non-negotiable priorities for organizations.
Importance of Data Security and Privacy Considerations in Data Pipelines
Protecting Sensitive Information
Data Pipelines often handle vast amounts of sensitive data, including customer information, financial records, and proprietary business data. Any unauthorized access or data breach could lead to severe consequences, including financial loss and reputational damage.
Regulatory Compliance
With data protection and privacy regulations becoming more stringent worldwide (such as GDPR, CCPA, and HIPAA), businesses must adhere to these laws to avoid hefty fines and legal implications.
Maintaining Customer Trust
Data breaches can severely impact customer trust and loyalty. A robust Data Pipeline with strong security measures assures customers that their data is handled with utmost care and confidentiality.
Role of Encryption, Access Controls, and Data Monitoring in Securing Data Pipelines
Encryption
Data encryption ensures that data remains secure both during transit between different pipeline components and when stored in databases or data repositories. It serves as a strong safeguard against data interception and unauthorized access.
Access Controls
Implementing access controls helps prevent unauthorized access to sensitive data. By setting granular access permissions based on user roles and responsibilities, it is recommended to ensure that data is accessible only to authorized personnel.
Data Monitoring
Data monitoring allows businesses to track data movement throughout the Data Pipeline in real-time. This monitoring enables rapid detection of any anomalies or suspicious activities, enabling prompt action to mitigate potential threats.
Future Trends in Data Pipeline Technology
In the rapidly evolving landscape of data management, Data Pipeline technology continues to witness groundbreaking advancements that shape the future of data-driven decision-making. As organizations seek to harness the full potential of their data, staying informed about emerging trends and potential innovations becomes critical for staying ahead in the industry.
Emerging Trends and Advancements in Data Pipeline Technology
Real-time Data Processing
The demand for real-time data processing is on the rise. Future Data Pipelines will focus on reducing data latency to provide up-to-the-moment insights, enabling businesses to make instant decisions based on the most current information.
Event-driven Architectures
Event-driven Data Pipelines leverage events and triggers to process data as it is generated or received. This approach ensures efficient handling of large-scale data streams and facilitates event-based data integration.
Serverless Data Pipelines
Serverless computing eliminates the need for managing infrastructure, allowing Data Pipelines to automatically scale based on demand. This results in cost efficiency and increased agility.
Ready to Embrace the Future of Data Management with Cutting-edge Data Pipeline Technology?
Federated Data Pipelines
The emergence of distributed data sources requires Data Pipelines to adopt federated approaches. Future Data Pipelines will seamlessly integrate data from various data stores, cloud services, and edge devices.
AI and Machine Learning Integration
Incorporating AI and machine learning models within Data Pipelines will enable intelligent data transformations, anomaly detection, and predictive analytics.
Potential Innovations Revolutionizing Data Management
Blockchain in Data Pipelines
The integration of blockchain technology into Data Pipelines can enhance data security, traceability, and transparency, making it ideal for industries like supply chain management and healthcare.
Data Privacy Enhancements
Future Data Pipelines may feature enhanced data privacy mechanisms, such as differential privacy, to protect sensitive data while still providing valuable insights.
Data Lineage and Governance
Innovations in data lineage tracking and governance tools will improve data traceability, enabling businesses to better manage data provenance and comply with regulatory requirements.
Leverage Credencys’ Expertise in Implementing Effective Data Pipelines
Credencys, a leading data management company, is here to empower your business with cutting-edge solutions and expertise in implementing effective Data Pipelines.
Why Choose Credencys?
Proven Track Record
With a proven track record of delivering top-notch data management solutions, Credencys has earned the trust of numerous clients across diverse industries. Our success stories are a testament to our commitment to excellence and innovation.
Expert Team
At Credencys, we boast a team of seasoned experts well-versed in the latest trends and advancements in data management and Data Pipeline technology. Their expertise ensures that your Data Pipeline is designed and implemented to meet your specific data requirements and business objectives.
Tailored Solutions
We understand that each organization’s data needs are unique. Therefore, our solutions are tailored to address your specific data challenges and help you derive maximum value from your data assets.
Security and Compliance
Data security and compliance are at the core of our Data Pipeline solutions. With robust encryption, access controls, and data monitoring, we ensure that your data is safeguarded against potential threats and remains compliant with relevant regulations.
How Credencys Empowers Your Business?
Streamlined Data Management
Our Data Pipeline solutions establish a well-structured pathway for data to flow seamlessly from diverse sources to target destinations, simplifying data management and enhancing data accessibility.
Real-time Insights
With real-time data processing capabilities, our Data Pipelines provide up-to-the-moment insights, enabling faster and data-driven decision-making for your business.
Enhanced Data Quality
We implement data transformation and cleansing processes to ensure data consistency, reliability, and accuracy, empowering you to trust the insights derived from your data.
Scalable and Efficient
Our Data Pipelines are designed for scalability, ensuring smooth handling of increasing data volumes without compromising on performance.
Take the Next Step
To experience the transformative power of Data Pipelines and data management, we invite you to explore Credencys’ range of data solutions. Our team is eager to understand your unique data challenges and collaboratively design a Data Pipeline that empowers your organization to thrive in the data-centric future.
Let Credencys be your Trusted Partner in Unlocking the Full Potential of Your Data





Tags: