Despite massive investments in artificial intelligence, a large percentage of enterprise AI initiatives fail to deliver expected outcomes. The reason isn’t flawed algorithms; it’s the lack of a strong data foundation.
Most organizations today still operate legacy data systems that were never designed to support AI workloads. These systems struggle with fragmented data, delayed processing, and limited scalability, making it nearly impossible to operationalize AI at scale.
This is where AI-ready data infrastructure becomes critical. An AI-ready data infrastructure goes beyond traditional storage and analytics.
It enables organizations to ingest, process, and activate high-quality data in real time, powering everything from predictive analytics to hyper-personalized customer experiences. In this blog, we’ll explore what AI-ready data infrastructure looks like, why traditional systems fall short, and how enterprises, especially in retail, can build a scalable foundation to unlock real AI value.
What Is AI-Ready Data Infrastructure?
AI-ready data infrastructure is a modern, scalable, and governed data ecosystem designed to ingest, process, store, and deliver high-quality data for AI and machine learning workloads. Unlike traditional systems, it is built with AI use cases in mind, ensuring that data is not only available but also reliable, timely, and usable for advanced analytics.
Core Characteristics
- Real-time and batch data processing to support both operational and analytical use cases
- Scalable storage architecture, often based on a lakehouse model
- Strong data governance and quality controls to ensure trust in AI outputs
- Seamless AI/ML integration, enabling faster model development and deployment
- Unified data access, eliminating silos across business functions
Why Traditional Data Infrastructure Fails AI Initiatives
Many enterprises attempt to layer AI capabilities on top of legacy infrastructure, but this approach rarely works.
Key Limitations
- Data silos prevent a unified view of customers and operations
- Batch-only processing delays insights and decision-making
- Poor data quality leads to inaccurate models
- Lack of ML pipeline support slows down experimentation and deployment
- High costs at scale due to inefficient architectures
Business Impact
For decision-makers, these limitations translate into:
- Slower time-to-market for AI-driven initiatives
- Lower ROI on data and AI investments
- Missed opportunities in personalization and optimization
- Reduced ability to innovate and compete
In short, without the right data infrastructure, even the most advanced AI strategies fail to deliver measurable business outcomes.
Key Components of AI-Ready Data Infrastructure
Building a robust data foundation requires more than just tools; it demands a well-orchestrated approach across ingestion, storage, and processing layers. Leveraging end-to-end data & analytics services ensures that data is not only accessible but also actionable for AI-driven insights.
1. Data Ingestion Layer
This layer is responsible for collecting data from multiple internal and external sources.
- Supports batch and real-time ingestion
- Integrates APIs, IoT devices, applications, and third-party systems
- Enables streaming data pipelines for real-time use cases
2. Data Storage Layer
Modern AI workloads demand flexible and scalable storage.
- Traditional options: data lakes and data warehouses
- Emerging standard: lakehouse architecture, combining the best of both
A lakehouse allows organizations to manage structured and unstructured data in a unified environment, making it ideal for AI use cases.
3. Data Processing & Transformation
Raw data needs to be cleaned, transformed, and enriched before it can be used.
- Shift from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform)
- Use of distributed processing frameworks for scalability
- Support for large-scale data transformations
4. Data Governance & Security
AI systems are only as trustworthy as the data behind them.
- Data cataloging for discoverability
- Data lineage tracking for transparency
- Role-based access control for security
- Compliance with regulatory requirements
5. AI/ML Enablement Layer
This is where data infrastructure directly supports AI development.
- Feature stores for reusable ML features
- Model training and deployment pipelines
- Experiment tracking and version control
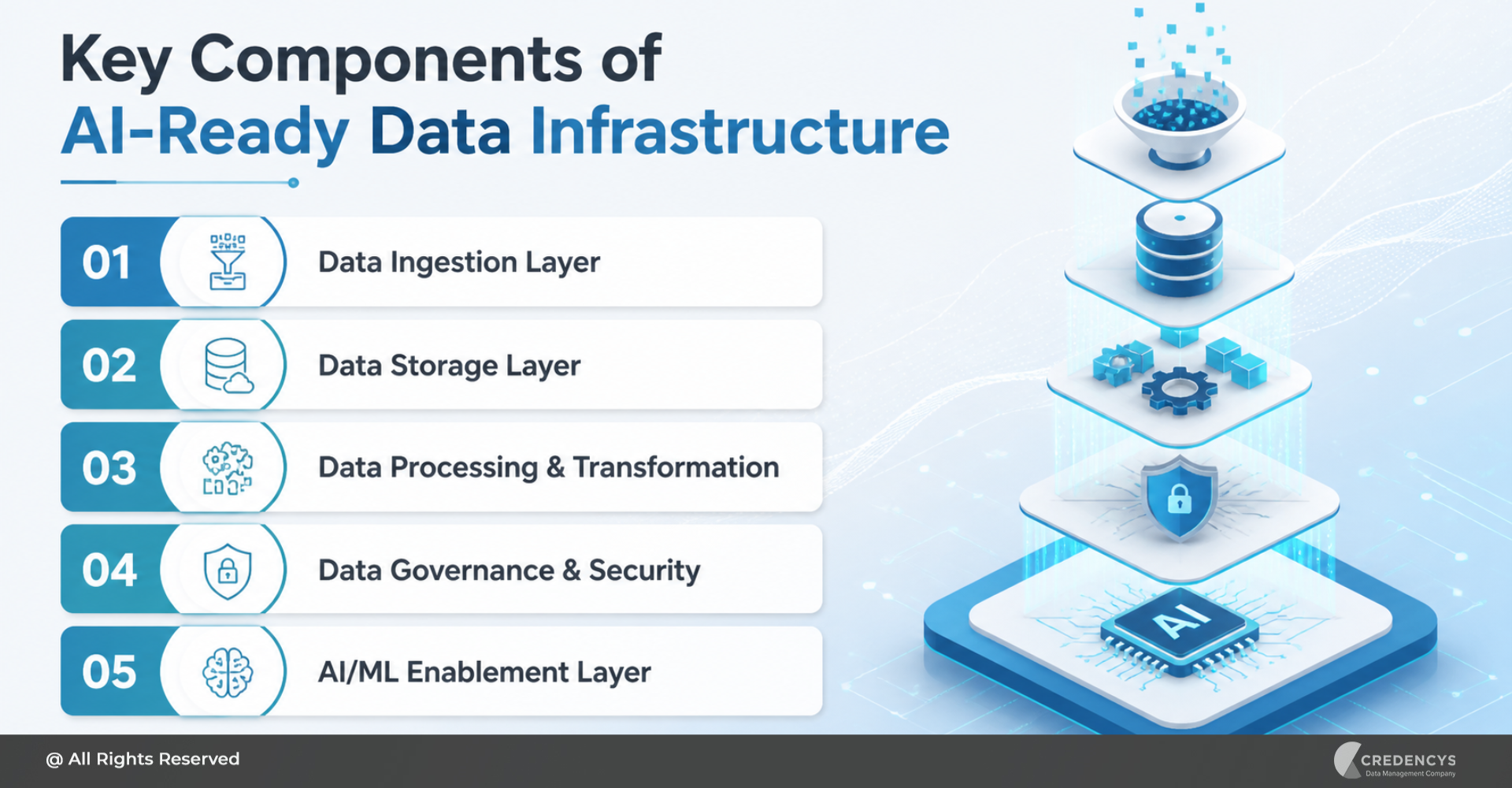
Together, these components create a robust foundation for scalable AI initiatives.
AI-Ready Data Infrastructure Use Cases in Retail
For retail and CPG enterprises, AI-ready infrastructure unlocks high-impact use cases.
1. Personalized Customer Experiences
By integrating data across channels, retailers can build a Customer 360 view and deliver:
- Real-time product recommendations
- Personalized offers and content
- Seamless omnichannel experiences
2. Demand Forecasting
AI models powered by high-quality data can:
- Predict demand more accurately
- Optimize inventory levels
- Reduce stockouts and overstock situations
3. Dynamic Pricing
With real-time data pipelines, retailers can:
- Adjust prices dynamically based on demand, competition, and inventory
- Maximize margins while remaining competitive
4. Marketing Optimization
AI-ready infrastructure enables:
- Hyper-targeted campaigns
- Better audience segmentation
- Improved campaign ROI
Challenges in Building AI-Ready Data Infrastructure
While the benefits are clear, building such infrastructure is not without challenges.
- Legacy system integration slows down modernization efforts
- Data silos across departments hinder unified insights
- Skill gaps in data engineering and AI capabilities
- Cost management for large-scale data processing
- Complex governance requirements
Organizations often underestimate the effort required to transition from traditional systems to AI-ready architectures. Without the right strategy and expertise, projects can become expensive and time-consuming.
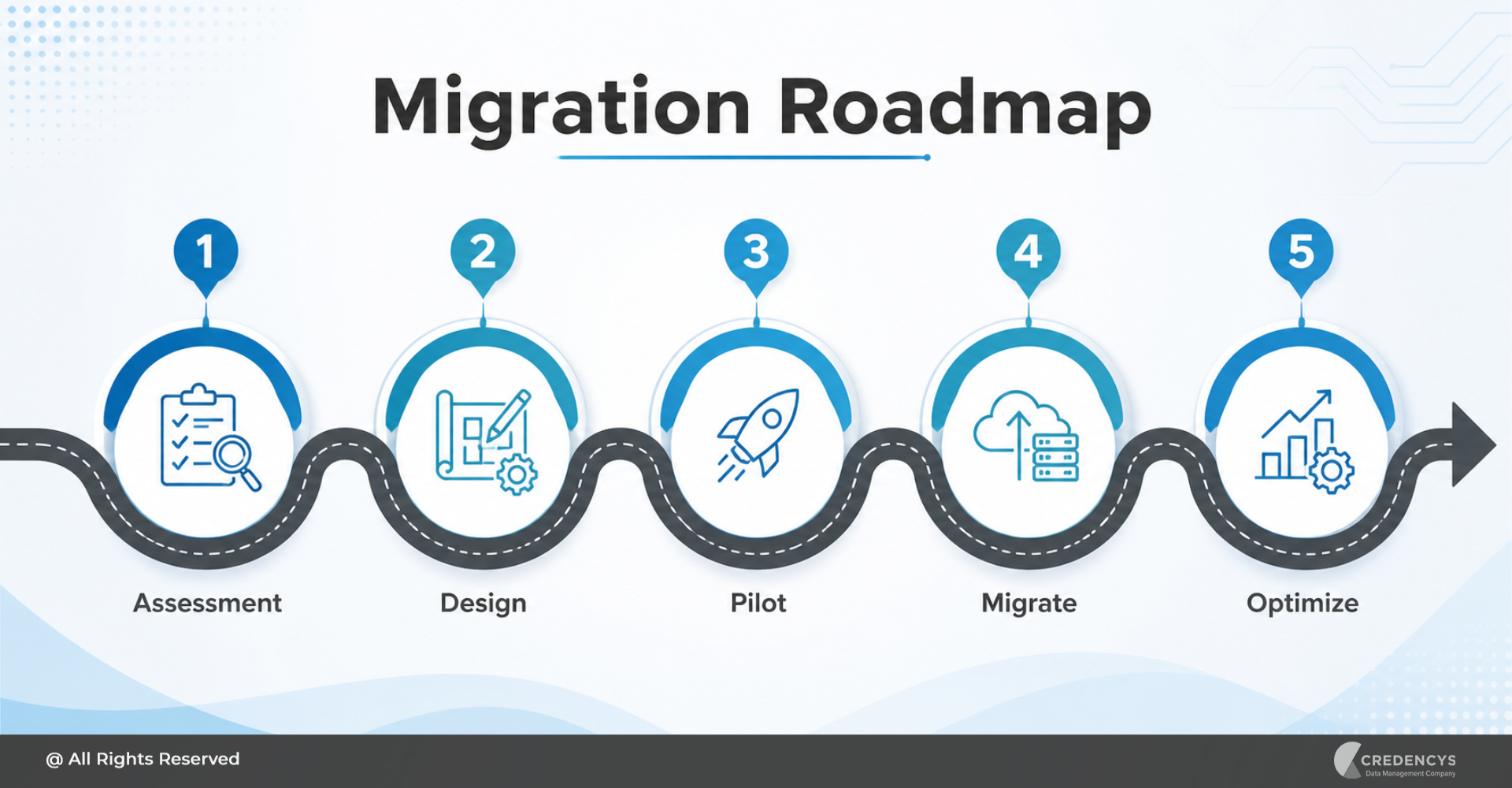
Steps to Build AI-Ready Data Infrastructure
1. Assess Current Data Maturity
Start by evaluating your existing data landscape, including data sources, architecture, quality, and governance practices. Identify gaps that could impact AI readiness, such as fragmented systems, inconsistent data, or a lack of real-time capabilities.
This baseline helps prioritize modernization efforts and investments.
2. Define Business-Driven AI Use Cases
Avoid a technology-first approach. Instead, identify high-impact AI use cases, like personalization, demand forecasting, or pricing optimization, that align with business goals.
Clear use cases ensure that your data infrastructure is purpose-built to deliver measurable outcomes and ROI.
3. Break Down Data Silos
Integrate data across departments such as marketing, sales, supply chain, and customer service to create a unified data ecosystem. Eliminating silos enables a holistic view of operations and customers, which is essential for accurate AI models and advanced analytics.
4. Adopt a Lakehouse Architecture
Move toward a lakehouse architecture that combines the scalability of data lakes with the performance of data warehouses. This approach allows you to manage structured and unstructured data in a single platform, simplifying data access and enabling diverse AI workloads.
5. Enable Real-Time Data Pipelines
Implement streaming and real-time data processing capabilities to support time-sensitive use cases like recommendations and dynamic pricing. Real-time pipelines ensure that AI models are powered by the most up-to-date data, improving decision accuracy and responsiveness.
6. Implement Governance Frameworks
Establish strong data governance practices, including data quality checks, cataloging, lineage tracking, and access controls. A well-governed data environment builds trust in AI outputs while ensuring compliance with regulatory requirements.
7. Align Data, AI, and Business Teams
Foster collaboration between data engineers, data scientists, and business stakeholders to ensure alignment on goals and execution. Breaking down organizational silos accelerates AI adoption and ensures that data initiatives directly support business outcomes.

Best Practices for AI-Ready Data Infrastructure
To maximize ROI, enterprises should follow these best practices:
- Design for scalability from day one
- Prioritize data quality over volume
- Enable self-service data access for business users
- Automate data pipelines and monitoring
- Align infrastructure investments with business KPIs
Future Trends in AI Data Infrastructure
As AI continues to evolve, so does the underlying data infrastructure.
- AI-native data platforms designed specifically for AI workloads
- Real-time decision intelligence becoming the norm
- Convergence of data mesh and lakehouse architectures
- Integration of generative AI into data platforms
- Autonomous data pipelines with minimal human intervention
Enterprises that adopt these trends early will gain a significant competitive advantage.
Why Enterprises Partner with Experts Like Credencys
Building an AI-ready data infrastructure requires more than just selecting the right tools; it demands a strategic approach and deep technical expertise. Organizations often partner with experienced providers to:
- Design and implement scalable data architectures
- Enable AI and machine learning capabilities
- Modernize legacy systems with minimal disruption
- Accelerate time-to-value for AI initiatives
With strong expertise in data engineering, AI/ML enablement, and platforms like Databricks and Snowflake, Credencys helps enterprises transform their data into a powerful AI engine, especially in retail and CPG environments.
Conclusion
AI success doesn’t start with models; it starts with data. Without a robust, scalable, and governed data infrastructure, even the most ambitious AI initiatives will struggle to deliver value.
On the other hand, organizations that invest in AI-ready data infrastructure can unlock faster insights, better decision-making, and truly personalized customer experiences. As competition intensifies and AI adoption accelerates, the question is no longer whether you should modernize your data infrastructure, but how quickly you can do so.
Now is the time to build a foundation that can support your AI ambitions, today and in the future.
FAQs
1. What is an AI-ready data infrastructure?
AI-ready data infrastructure is a modern data ecosystem designed to support AI and machine learning workloads by enabling scalable, real-time, and high-quality data processing.
2. Why is an AI-ready data infrastructure important?
It ensures that AI models have access to accurate, timely, and governed data, leading to better insights, faster decisions, and higher ROI.
3. How do you make your data infrastructure AI-ready?
You can make data infrastructure AI-ready by adopting a lakehouse architecture, enabling real-time pipelines, improving data quality, and aligning data systems with AI use cases.
4. What architecture is best for AI workloads?
Lakehouse architecture is widely considered the best option as it combines the scalability of data lakes with the performance of data warehouses.
5. What are the key components of an AI-ready data infrastructure?
Key components include data ingestion, storage, processing, governance, and AI/ML enablement layers.