
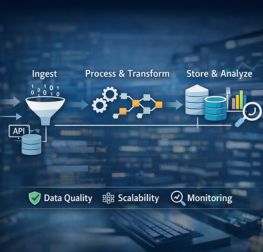
The volume, velocity, and variety of data are growing at an unprecedented pace. From real-time customer interactions to AI-driven decision-making, modern enterprises are now managing hundreds of data pipelines across cloud platforms, applications, and business systems.
As organizations scale their analytics and AI initiatives, the demand for faster, more reliable data has never been higher. But here’s the problem: traditional data engineering approaches are breaking down.
Legacy workflows were never designed for today’s complexity. Teams often deal with:
- Fragmented pipelines across multiple tools
- Manual processes that slow down deployment
- Poor data quality and unreliable outputs
- Limited visibility into pipeline failures
The result? Delayed insights, frustrated teams, and missed business opportunities.
Studies show that only about 20% of raw business data actually reaches analytics systems, highlighting massive inefficiencies in traditional data workflows.
This is exactly where DataOps comes in. Inspired by DevOps, DataOps introduces a modern approach to managing data pipelines focused on automation, collaboration, and reliability.
It enables organizations to:
- Automate data workflows end-to-end
- Improve data quality through continuous monitoring and testing
- Accelerate time-to-insight
- Foster better collaboration between data engineers, analysts, and business teams
The impact is significant. Organizations adopting DataOps tools report faster insights, improved operational efficiency, and stronger business outcomes, with many seeing measurable improvements in productivity and data reliability.
In this blog, we’ll help you navigate the DataOps landscape by covering:
- The top DataOps tools in 2026
- Key tool categories and use cases
- A detailed comparison of leading platforms
- A practical guide on how to choose the right DataOps tool for your business
Let’s dive in.
What is DataOps?
DataOps is a set of practices, processes, and technologies designed to improve the speed, quality, and reliability of data analytics. It brings together principles from DevOps, Agile, and data engineering to create a more automated, collaborative, and scalable data ecosystem.
Instead of treating data pipelines as one-off projects, DataOps approaches them as continuous, production-grade systems that require monitoring, testing, and ongoing optimization.
Key Principles of DataOps
DataOps is built on a few foundational principles that enable modern data teams to operate efficiently:
Automation
- Automates data ingestion, transformation, and deployment
- Reduces manual errors and accelerates delivery cycles
Continuous Integration & Continuous Delivery (CI/CD)
- Enables rapid updates to data pipelines without breaking systems
- Ensures faster release of analytics and insights
Data Quality & Observability
- Continuously monitors data freshness, accuracy, and anomalies
- Helps teams detect and resolve issues before they impact business decisions
Collaboration Across Teams
- Breaks silos between data engineers, analysts, and business users
- Encourages shared ownership of data pipelines and outcomes
Why DataOps is Critical for Modern Businesses
As organizations move toward AI-driven and real-time decision-making, DataOps has become essential. Here’s why:
Faster Time-to-Insight
- Automated pipelines reduce delays in data processing
- Business users get timely, actionable insights
Improved Data Reliability
- Built-in testing and monitoring ensure high-quality data
- Reduces the risk of flawed analytics and decisions
Better Support for AI/ML Initiatives
- Reliable, well-managed data pipelines are the backbone of AI models
- Enables continuous model training and improvement
Reduced Operational Bottlenecks
- Eliminates manual intervention and firefighting
- Frees up teams to focus on innovation instead of maintenance
DataOps transforms data from a bottleneck into a strategic asset, enabling organizations to scale analytics, improve decision-making, and stay competitive in a data-driven world.
Key Categories of DataOps Tools
Before diving into the top DataOps tools, it’s important to understand that no single tool solves everything. A modern DataOps stack comprises multiple categories, each addressing a specific part of the data lifecycle.
Breaking tools into these categories will help you evaluate, compare, and choose the right combination based on your business needs.
1. Data Pipeline Orchestration Tools
These tools act as the central nervous system of your data operations. They help you:
- Schedule and automate workflows
- Manage dependencies between tasks
- Monitor pipeline execution
Why it matters: Without orchestration, pipelines become chaotic and difficult to scale.
Typical use cases:
- Automating ETL/ELT workflows
- Managing complex, multi-step data pipelines
- Handling retries and failure recovery
2. Data Observability Tools
Data observability tools provide visibility into the health of your data pipelines. They help answer critical questions like:
- Is the data fresh?
- Has something broken?
- Are there anomalies in the data?
Why it matters: You can’t fix what you can’t see. Observability ensures trust in your data.
Typical use cases:
- Detecting data anomalies and schema changes
- Monitoring pipeline health in real time
- Root cause analysis for failures
3. Data Testing & Validation Tools
These tools ensure that your data is accurate, consistent, and reliable before it reaches business users.
Why it matters: Bad data leads to bad decisions; testing is non-negotiable in DataOps.
Typical use cases:
- Validating data quality rules
- Schema testing
- Preventing pipeline breakages during updates
4. Data Integration & Transformation Tools
These tools focus on moving and transforming data across systems. They enable:
- Data ingestion from multiple sources
- Data transformation into usable formats
- Building scalable ETL/ELT pipelines
Why it matters: They form the backbone of any data platform.
Typical use cases:
- Integrating data from CRMs, ERPs, APIs
- Transforming raw data into analytics-ready datasets
- Supporting data warehouse/lakehouse architectures
5. Data CI/CD & Version Control Tools
These tools bring software engineering discipline into data workflows. They help teams:
- Version control data pipelines
- Automate deployments
- Collaborate more effectively
Why it matters: As data systems grow, manual deployments become risky and unsustainable.
Typical use cases:
- Managing changes in data models
- Automating testing and deployment pipelines
- Enabling team collaboration across environments

Top DataOps Tools in 2026 (Expert Picks)
With a rapidly evolving data ecosystem, organizations are no longer looking for standalone tools; they need solutions that fit into a connected, scalable DataOps strategy. The right tools not only streamline workflows but also improve data reliability, enable faster deployments, and support advanced analytics and AI initiatives.
Here are 5 of the most impactful DataOps tools in 2026, carefully selected for their capabilities, adoption, and relevance to modern data teams.
1. Apache Airflow
Apache Airflow remains one of the most widely adopted tools for data pipeline orchestration, especially in complex enterprise environments. It allows teams to define workflows as code using Python, making it highly flexible and extensible.
Key Features:
- DAG (Directed Acyclic Graph)-based workflow management
- Dynamic scheduling and dependency handling
- Extensive library of integrations with cloud and data tools
Pros:
- Highly customizable for complex workflows
- Strong open-source community and ecosystem
- Scales well with the right infrastructure
Cons:
- Requires dedicated resources for setup and maintenance
- Can become complex to manage at scale without proper governance
Best For:
- Organizations that need full control over complex data pipelines and have the engineering maturity to manage them.
2. Databricks
Databricks has evolved into a unified DataOps platform by combining data engineering, analytics, and AI within a lakehouse architecture. Its native workflow capabilities allow teams to orchestrate pipelines while seamlessly integrating with large-scale data processing and machine learning.
Key Features:
- Unified lakehouse architecture (data lake + warehouse)
- Built-in workflow orchestration and job scheduling
- Native support for big data processing and AI/ML
Pros:
- End-to-end platform reduces tool sprawl
- Highly scalable for enterprise-grade workloads
- Strong integration with modern data stacks
Cons:
- Higher cost compared to standalone tools
- Requires expertise to fully leverage its capabilities
Best For:
- Enterprises building data-intensive, AI-driven platforms that require scalability and unified operations.
3. Prefect
Prefect is a modern orchestration tool designed to address many of the usability and reliability challenges of traditional schedulers. It offers a developer-first approach with improved visibility and control over data workflows.
Key Features:
- Python-native workflow creation
- Dynamic and reactive pipeline execution
- Built-in observability and monitoring
Pros:
- Easier to set up and use compared to legacy tools
- Strong focus on developer experience
- Flexible deployment options (cloud or self-hosted)
Cons:
- Smaller ecosystem compared to more established tools
- Advanced enterprise features may require paid plans
Best For:
- Teams looking for a modern, flexible orchestration tool with faster onboarding and better usability.
4. Monte Carlo
Monte Carlo is a leading data observability platform that helps organizations ensure the reliability and trustworthiness of their data pipelines. It provides deep visibility into data health, making it easier to detect and resolve issues before they impact business outcomes.
Key Features:
- Automated anomaly detection across datasets
- End-to-end pipeline monitoring
- Root cause analysis and alerting
Pros:
- Strong focus on data reliability at scale
- Reduces downtime and data incidents
- Enterprise-ready with advanced monitoring capabilities
Cons:
- Premium pricing may not suit smaller teams
- Primarily focused on observability (not a full pipeline solution)
Best For:
- Organizations where data quality and uptime are mission-critical, such as those that rely on real-time analytics or AI-driven decision-making.
5. dbt
dbt has become a cornerstone of modern DataOps by enabling teams to transform data directly within their data warehouse using SQL. It brings software engineering best practices like version control, testing, and modular development into analytics workflows.
Key Features:
- SQL-based data transformation
- Built-in testing and documentation
- Integration with version control systems (like Git)
Pros:
- Empowers analytics engineers and data teams
- Strong community and widespread adoption
- Improves collaboration and governance
Cons:
- Limited to the transformation layer (not orchestration or ingestion)
- Requires a modern data warehouse/lakehouse setup
Best For:
- Teams focused on data modeling, transformation, and analytics engineering within a modern data stack.
These tools represent the core building blocks of a modern DataOps ecosystem, from orchestration and transformation to observability. The right combination depends on your organization’s data maturity, architecture, and business goals.
| Tool | Category | Best For | Key Strength | Limitation |
|---|---|---|---|---|
| Apache Airflow | Orchestration | Complex, large-scale data pipelines | Highly flexible & customizable | Requires setup, maintenance, and expertise |
| Databricks | Unified Data Platform | Enterprise data + AI workloads | End-to-end scalability & integration | Higher cost and learning curve |
| Prefect | Orchestration | Modern, developer-friendly workflows | Easy to use with strong observability | Smaller ecosystem compared to Airflow |
| Monte Carlo | Observability | Monitoring data quality at scale | Automated anomaly detection | Limited to observability use cases |
| dbt | Transformation | Data modeling and analytics engineering | SQL-based transformation & testing | Not a full DataOps solution (no orchestration) |
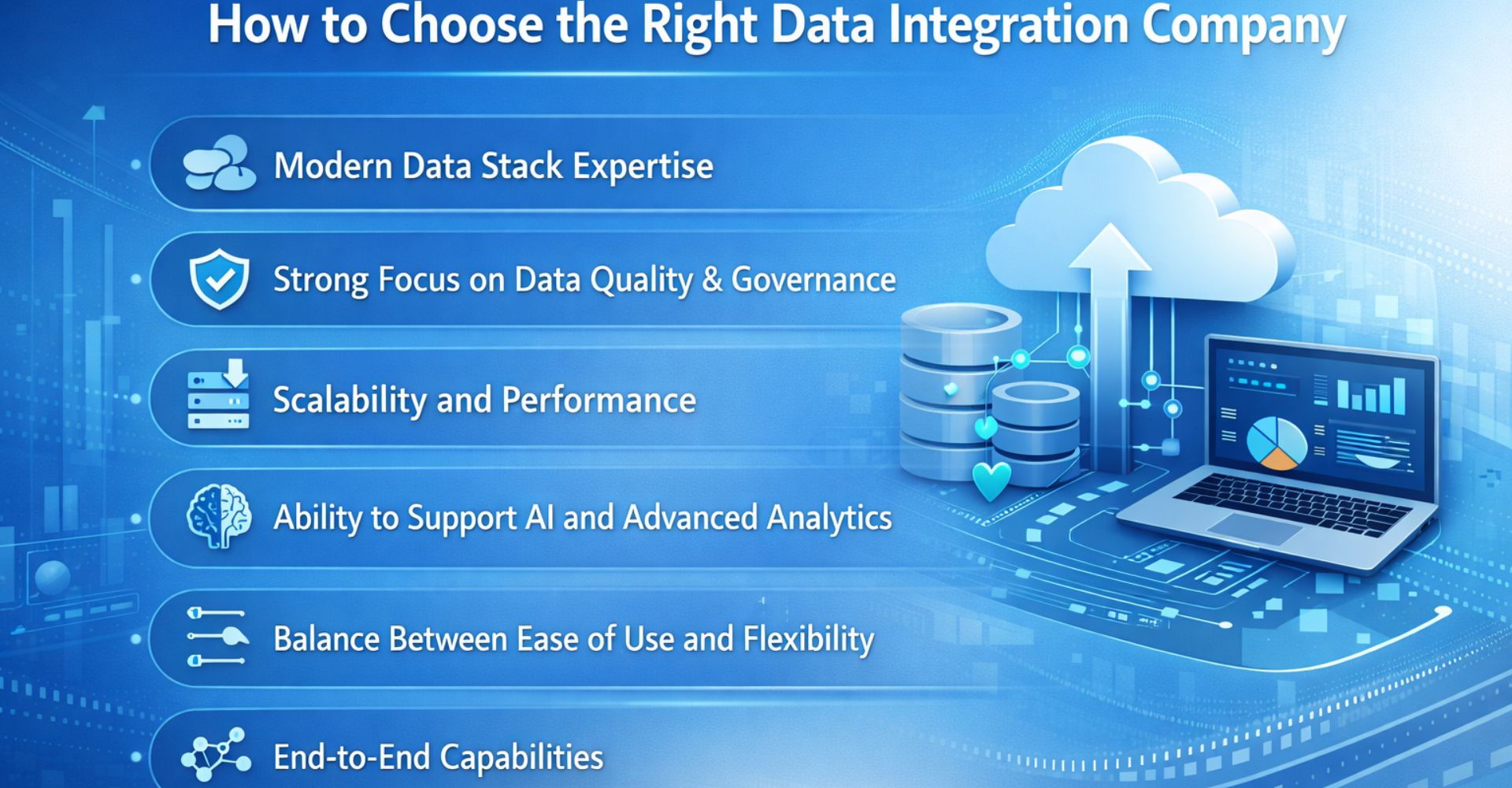
How to Choose the Right DataOps Tool
With so many options available, selecting the right DataOps tool can quickly become overwhelming. The key is to move beyond feature comparisons and focus on how well a tool aligns with your business goals, data architecture, and team capabilities.
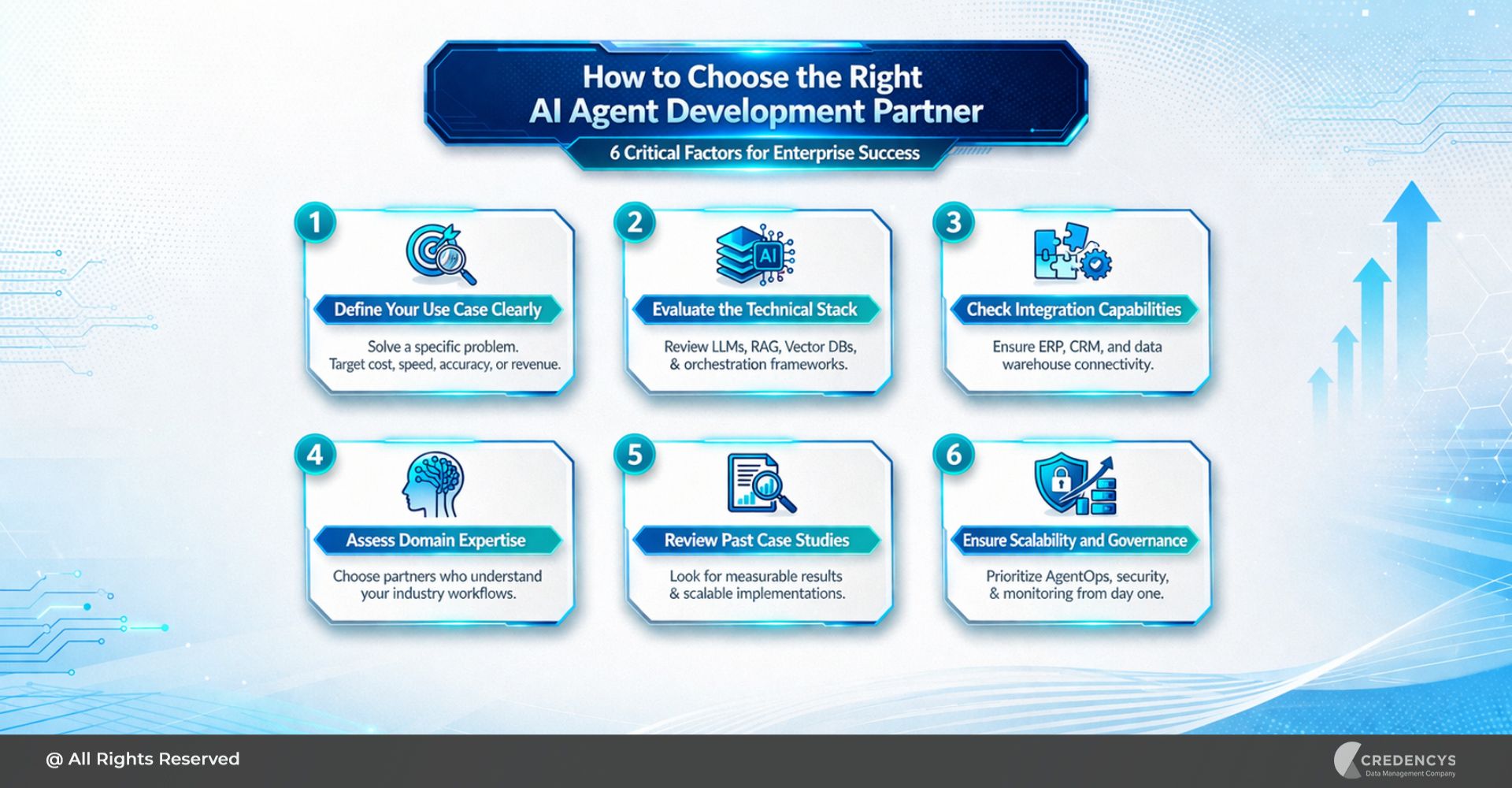
Here’s a practical framework to guide your decision-making:
1. Define Your Data Stack & Use Cases
Start by understanding your current and future data needs. Ask yourself:
- Are you working with batch processing, real-time data, or both?
- Do you need to support AI/ML workloads?
- What does your existing stack look like (cloud, warehouse, lakehouse)?
Why it matters: Not all tools are designed for every use case. Choosing the wrong one can lead to scalability issues later.
2. Evaluate Scalability & Performance
As your data grows, your tools should scale without compromising performance. Consider:
- Data volume and pipeline complexity
- Ability to handle concurrent workflows
- Performance under peak loads
Why it matters: A tool that works for a small team may fail at enterprise scale.
3. Check Integration Capabilities
Your DataOps tool should integrate seamlessly with your existing ecosystem. Look for compatibility with:
- Data warehouses/lakehouses
- BI tools
- AI/ML platforms
- Cloud providers
Why it matters: Poor integration leads to data silos and operational inefficiencies.
4. Focus on Data Observability & Governance
Data reliability is non-negotiable, especially for decision-making and AI. Evaluate:
- Built-in monitoring and alerting
- Data quality checks
- Lineage and audit capabilities
Why it matters: Without observability, you risk making decisions on inaccurate or outdated data.
5. Consider Total Cost of Ownership (TCO)
The cost of a tool goes beyond licensing. Include:
- Infrastructure costs
- Maintenance and support
- Hiring or training resources
Why it matters: A cheaper tool upfront may become expensive in the long run due to operational overhead.
6. Assess Ease of Implementation & Adoption
Even the most powerful tool is useless if your team can’t use it effectively. Check:
- Learning curve
- Documentation and community support
- Availability of managed services
Why it matters: Faster adoption leads to quicker ROI and reduced friction across teams.

Why Credencys is Your Ideal DataOps Implementation Partner
Choosing the right DataOps tools is only half the battle. The real challenge lies in implementing, integrating, and scaling them effectively within your existing data ecosystem.
That’s where the right partner makes all the difference. Credencys helps organizations move beyond tool selection to build a fully operational, scalable, and outcome-driven DataOps framework.
1. End-to-End DataOps Expertise
Credencys supports your entire DataOps journey, from strategy to execution and continuous optimization.
- Assess your current data maturity and gaps
- Define a tailored DataOps roadmap
- Implement and integrate the right tools
- Continuously optimize pipelines for performance and reliability
Result: A structured, future-ready DataOps foundation aligned with your business goals.
2. Strong Experience with Modern Data Stack
Credencys brings hands-on expertise across leading DataOps and analytics platforms, including:
- Databricks and modern lakehouse architectures
- Cloud data platforms like Snowflake
- Transformation tools like dbt
- Orchestration and pipeline automation tools
Result: Seamless integration across your data ecosystem with minimal disruption.
3. Industry-Focused Approach
Unlike generic consulting firms, Credencys takes a domain-driven approach, especially across:
- Retail
- eCommerce
- Manufacturing
- Supply Chain
- CPG
This ensures your DataOps implementation is not just technically sound but also aligned with industry-specific challenges and use cases.
Result: Faster time-to-value with solutions tailored to your business context.
4. Accelerated Implementation Frameworks
Credencys leverages proven frameworks and best practices to speed up deployment.
- Pre-built accelerators for common use cases
- Standardized implementation methodologies
- Automation-first approach
Result: Reduced implementation time and quicker ROI.
5. Focus on Business Outcomes
Credencys prioritizes measurable impact over technical complexity.
- Improved data reliability and quality
- Faster analytics and reporting cycles
- Enhanced readiness for AI/ML initiatives
Result: Tangible business value, not just a modernized tech stack.
With the right strategy and partner in place, DataOps becomes a competitive advantage rather than just a process.
Conclusion
From orchestrating complex pipelines to ensuring data quality and observability, the right set of tools can help organizations:
- Accelerate time-to-insight
- Improve data reliability and trust
- Enable seamless collaboration across teams
- Support advanced analytics and AI initiatives
However, it’s important to remember that DataOps success is about building a cohesive strategy, integrating the tools effectively, and aligning them with your business goals. Whether you are just starting your DataOps journey or looking to optimize your existing setup, taking a structured, outcome-driven approach will help you unlock the full value of your data.
If you are looking to implement or scale DataOps within your organization, partnering with experts like Credencys can help you move faster, reduce risks, and achieve measurable results.















![Best Business Intelligence Companies in 2026 [Expert Picks]](https://www.credencys.com/wp-content/uploads/2026/03/Best-Business-Intelligence-Companies_thumb.jpg)
