Data has become the foundation of modern business decisions. But many organizations still struggle with a fundamental question: where should all that data live, and how should it be managed for analytics and AI?
For decades, the data warehouse was the gold standard for enterprise analytics. It helped businesses centralize structured data, generate reports, and support BI dashboards. But as data volumes exploded and new data types emerged, traditional warehouses began showing their limitations.
Today, companies must manage massive datasets from multiple sources such as applications, IoT devices, websites, customer platforms, and operational systems. Much of this data is semi-structured or unstructured, making it harder to store and analyze using conventional data warehouse architectures.
This challenge led to the rise of the data lake, and more recently, the data lakehouse, a modern architecture that combines the flexibility of data lakes with the performance and reliability of data warehouses.
As organizations build AI-ready and analytics-driven platforms, choosing the right data architecture becomes a strategic decision. The debate around data warehouse vs data lakehouse is not just about storage. It impacts scalability, cost efficiency, data governance, and how quickly teams can turn raw data into insights.
In this guide, we’ll break down the key differences between a data warehouse and a data lakehouse, how each architecture works, their advantages and limitations, and how to determine which approach best fits your business needs.
What is a Data Warehouse?
A data warehouse is a centralized data storage system designed to store, organize, and analyze structured data from multiple sources for reporting and business intelligence.
It acts as the single source of truth for historical business data, allowing organizations to generate dashboards, run analytical queries, and support decision-making across departments such as finance, sales, marketing, and operations.
Unlike operational databases that handle daily transactions, a data warehouse is built specifically for analytics workloads. Data from various systems such as CRM platforms, ERP systems, marketing tools, and applications is collected, transformed, and loaded into the warehouse where it can be queried efficiently.
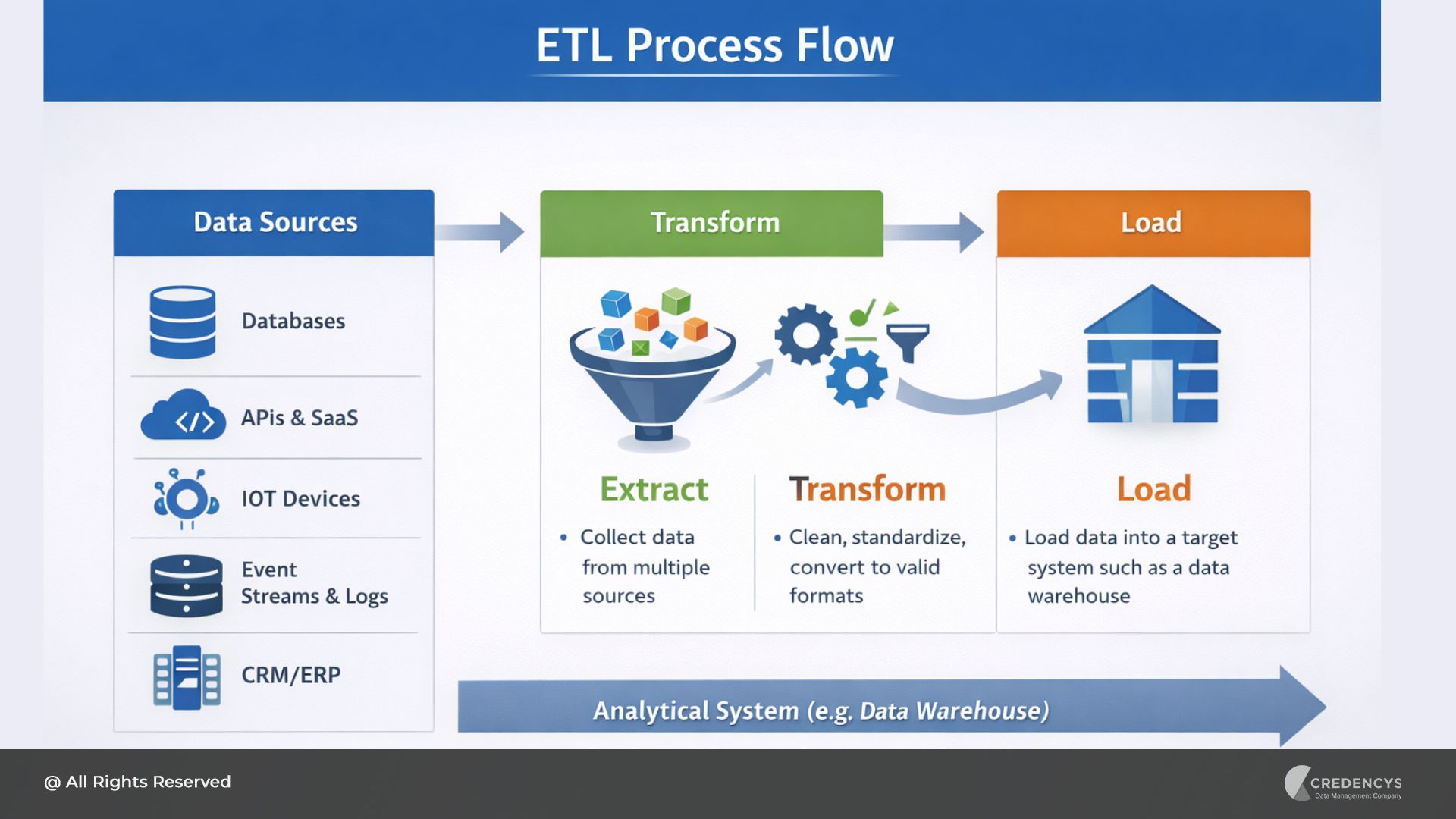
Most traditional data warehouses follow the ETL (Extract, Transform, Load) process. Data is first extracted from source systems, transformed into a consistent format, and then loaded into structured tables optimized for analytics.
Key Characteristics of a Data Warehouse
- Structured Data Storage: Data warehouses primarily store structured data organized into tables, schemas, and relationships.
- Optimized for Analytical Queries: They are designed for complex queries, aggregations, and reporting rather than transactional processing.
- Schema-on-Write Approach: Data must be structured and modeled before it is loaded, ensuring data consistency and quality.
- Historical Data Analysis: Warehouses store large volumes of historical data, enabling trend analysis and long-term reporting.
- High Performance for BI Tools: They integrate seamlessly with business intelligence tools to power dashboards and reports.
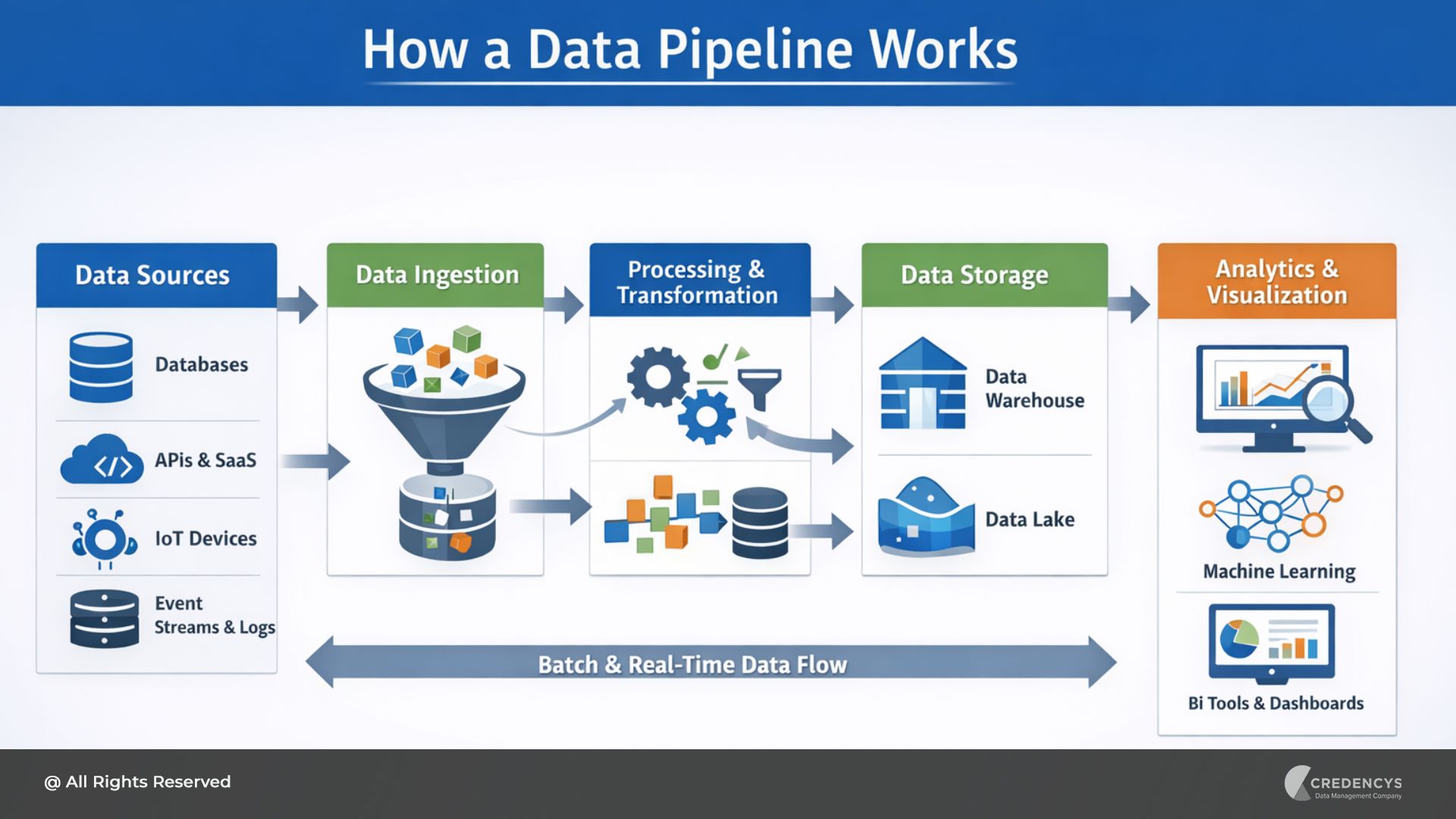
Typical Data Warehouse Architecture
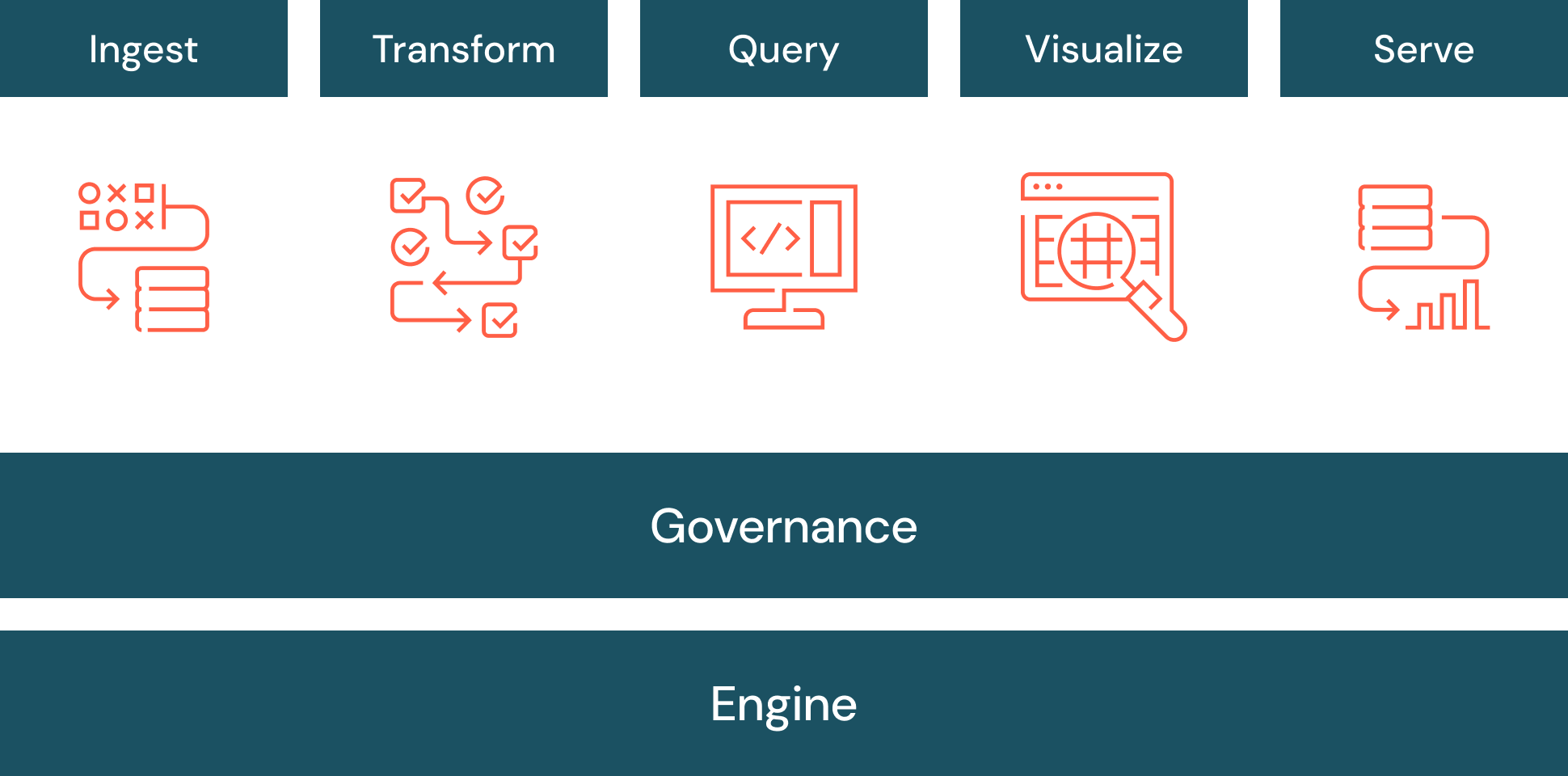
A typical data warehouse architecture consists of the following layers:
- Data Sources: Operational systems such as CRM, ERP, transactional databases, marketing tools, and applications.
- ETL / Data Integration Layer: Data is extracted from sources, transformed into a standardized format, and loaded into the warehouse.
- Central Data Warehouse: The core repository where cleaned and structured data is stored.
- Data Marts (Optional): Department-specific subsets of the warehouse created for teams such as finance, marketing, or sales.
- Analytics & BI Layer: Business intelligence tools query the warehouse to generate dashboards, reports, and insights.
Common Data Warehouse Technologies
Popular modern data warehouse platforms include:
- Snowflake
- Amazon Redshift
- Google BigQuery
- Azure Synapse Analytics
These cloud-native warehouses provide scalable storage, fast query performance, and strong integration with BI tools.
Limitations of Traditional Data Warehouses
While data warehouses remain powerful for structured analytics, they also present several challenges in modern data environments:
- High cost when storing very large datasets
- Limited support for unstructured and semi-structured data
- Complex data transformation pipelines
- Difficulty supporting AI and machine learning workloads at scale
What is a Data Lakehouse?
A data lakehouse is a modern data architecture that combines the flexibility and scalability of data lakes with the performance, governance, and reliability of data warehouses.
Traditional data lakes allow organizations to store massive volumes of structured, semi-structured, and unstructured data at a lower cost. However, they often lack strong governance, data quality controls, and optimized query performance. Data warehouses, on the other hand, provide structured analytics and reliable performance but can become expensive and restrictive when handling diverse data types.
The data lakehouse architecture bridges this gap by enabling organizations to store raw data in a data lake while applying warehouse-like capabilities such as ACID transactions, schema enforcement, data governance, and high-performance SQL analytics.
This unified approach allows businesses to support business intelligence, real-time analytics, machine learning, and AI workloads using a single data platform.
Key Characteristics of a Data Lakehouse
- Supports Multiple Data Types: A lakehouse can store structured, semi-structured, and unstructured data in the same environment.
- Open Storage Architecture: Data is typically stored in open formats such as Parquet or Delta tables on cloud object storage.
- Schema Enforcement with Flexibility: Lakehouses support schema-on-read and schema-on-write, allowing both flexibility and governance.
- Unified Platform for Analytics and AI: Unlike traditional warehouses, lakehouses support SQL analytics, data engineering, machine learning, and streaming workloads on the same platform.
- Cost-Effective Scalability: Since storage and compute are separated, organizations can scale their infrastructure more efficiently.
Typical Data Lakehouse Architecture
A typical lakehouse architecture includes the following layers:
- Data Sources: Applications, IoT devices, operational databases, APIs, logs, and streaming data.
- Ingestion & Processing Layer: Batch and streaming pipelines ingest data using tools such as Spark, Kafka, or data integration platforms.
- Cloud Data Lake Storage: Raw and processed data is stored in cloud object storage systems.
- Lakehouse Table Layer: Technologies such as Delta Lake, Iceberg, or Hudi provide ACID transactions, schema management, and indexing.
- Unified Analytics Layer: Data scientists, analysts, and applications query the data using SQL engines, BI tools, notebooks, and AI frameworks.
Popular Data Lakehouse Technologies
Several modern platforms support lakehouse architectures, including:
- Databricks Lakehouse Platform
- Apache Iceberg
- Delta Lake
- Apache Hudi
- Snowflake with open table formats
These platforms enable organizations to run analytics, machine learning, and data engineering workloads on a unified architecture.
Data Warehouse vs Data Lakehouse: Key Differences
While both data warehouses and data lakehouses are designed to support analytics and business intelligence, they differ significantly in terms of architecture, data processing, scalability, and use cases.
A traditional data warehouse is optimized for structured data and reporting, whereas a data lakehouse is built to handle large volumes of diverse data types while supporting advanced analytics and AI workloads.
Understanding these differences helps organizations choose the right architecture based on their data complexity, analytics needs, and long-term data strategy.
Data Warehouse vs Data Lakehouse Comparison
| Feature | Data Warehouse | Data Lakehouse |
|---|---|---|
| Data Types Supported | Primarily structured data | Structured, semi-structured, and unstructured data |
| Schema Approach | Schema-on-write (data structured before storage) | Schema-on-read + schema-on-write flexibility |
| Storage Cost | Higher storage cost | More cost-effective due to cloud object storage |
| Performance for BI Queries | Highly optimized for BI and reporting | Optimized for both analytics and large-scale data processing |
| Data Processing | Batch processing with ETL pipelines | Supports batch and real-time streaming |
| Scalability | Scales well but can become expensive | Highly scalable with decoupled storage and compute |
| AI & Machine Learning Support | Limited support | Built to support ML, AI, and advanced analytics |
| Typical Data Volume | Moderate to large datasets | Extremely large and diverse datasets |
| Data Governance | Strong governance and data quality controls | Governance supported through modern table formats |
| Typical Users | Business analysts and BI teams | Data engineers, analysts, and data scientists |
Summary of the Differences
In simple terms, a data warehouse focuses on structured analytics, making it ideal for traditional reporting and dashboards.
A data lakehouse provides a unified data platform, allowing organizations to run analytics, machine learning, and large-scale data processing workloads on the same architecture.
For companies dealing with rapidly growing data volumes, diverse data formats, and AI-driven initiatives, lakehouse architectures often provide greater flexibility and scalability.
Data Warehouse vs Data Lakehouse: Real-World Use Cases
Both data warehouses and data lakehouses play an important role in modern data architectures, but they are designed for different types of workloads and business needs. Understanding their real-world applications can help organizations decide which architecture best aligns with their analytics strategy.
Real-World Use Cases for Data Warehouses
Data warehouses are widely used in scenarios where organizations need highly structured, reliable, and consistent data for reporting and business intelligence.
1. Business Intelligence and Executive Reporting
Companies use data warehouses to power dashboards and reports for leadership teams. Structured data from CRM, ERP, and finance systems is aggregated to track KPIs such as revenue, customer acquisition, and operational performance.
2. Financial and Regulatory Reporting
Industries like banking, insurance, and healthcare rely on data warehouses to generate accurate financial statements, compliance reports, and audit trails, where data consistency and governance are critical.
3. Sales and Marketing Analytics
Marketing teams analyze campaign performance, customer segmentation, and conversion rates using structured datasets stored in a warehouse.
4. Supply Chain and Operations Monitoring
Retail and manufacturing organizations use warehouses to track inventory levels, supplier performance, and logistics efficiency through standardized reporting.
Real-World Use Cases for Data Lakehouses
Data lakehouses are ideal for organizations that need to manage large volumes of diverse data while supporting advanced analytics, machine learning, and real-time insights.
1. Machine Learning and AI Model Training
Data scientists require access to raw and diverse datasets such as customer behavior logs, product data, images, and sensor data. Lakehouses provide a unified environment for preparing and training AI models.
2. Customer 360 and Behavioral Analytics
Companies combine structured transactional data with unstructured interaction data such as website activity, mobile app usage, and support conversations to create comprehensive customer profiles.
3. Real-Time Data Processing and Streaming Analytics
Industries like fintech, logistics, and e-commerce process streaming data from applications, transactions, and IoT devices to generate real-time insights.
4. Large-Scale Data Engineering and Data Science Workloads
Lakehouses enable organizations to store raw datasets at scale and process them for advanced analytics, experimentation, and predictive modeling.
Choosing the Right Approach for Your Use Case
In many modern enterprises, the choice is not always data warehouse vs data lakehouse. Instead, organizations often adopt a hybrid data architecture, where a lakehouse handles large-scale data processing and machine learning workloads, while a warehouse powers curated datasets for business intelligence and reporting.
The right approach depends on factors such as data volume, data variety, analytics complexity, governance requirements, and long-term AI initiatives.
How to Choose Between a Data Warehouse and a Data Lakehouse
Choosing between a data warehouse and a data lakehouse depends on your organization’s data maturity, analytics needs, and long-term data strategy. While both architectures support data-driven decision-making, they serve different types of workloads and data environments.
Rather than asking which architecture is “better,” the key question is which one aligns best with your business goals, data complexity, and future analytics requirements.
Below are some practical factors to consider when making this decision.
1. Type and Variety of Data
If your organization primarily works with structured data from operational systems, a data warehouse is often sufficient.
However, if your business needs to manage large volumes of structured, semi-structured, and unstructured data such as logs, IoT data, images, and clickstream data, a lakehouse architecture provides greater flexibility.
Choose a Data Warehouse if:
- Most data comes from structured sources like CRM, ERP, and transactional systems
- The primary goal is reporting and dashboards
Choose a Data Lakehouse if:
- You need to store and process diverse data formats
- Your data sources include streaming data, logs, and machine-generated data
2. Analytics and Workload Requirements
Data warehouses are optimized for business intelligence, reporting, and SQL-based analytics. They work well for teams focused on dashboards, KPI tracking, and operational reporting.
Data lakehouses support a broader range of workloads, including data engineering, advanced analytics, and machine learning.
Choose a Data Warehouse if:
- Your teams mainly run BI dashboards and scheduled reports
- Query performance for structured analytics is the main priority
Choose a Data Lakehouse if:
- Your organization runs data science and machine learning workloads
- You need a unified platform for analytics and AI
3. Data Volume and Scalability
Traditional data warehouses scale effectively but can become expensive when storing massive datasets.
Lakehouses are designed to handle petabyte-scale data environments by separating storage and compute, making them more cost-efficient for large data volumes.
Choose a Data Warehouse if:
- Your data volumes are manageable and predictable
Choose a Data Lakehouse if:
- Your organization deals with rapidly growing data volumes
4. Cost and Infrastructure Considerations
Data warehouses often require high-performance storage and compute resources, which can increase costs as data grows.
Lakehouse architectures leverage cloud object storage, allowing organizations to store large amounts of raw data at a lower cost while scaling compute independently.
5. Future AI and Data Innovation Goals
Organizations investing in AI, machine learning, and advanced analytics often benefit from lakehouse architectures because they support data engineering, analytics, and data science on the same platform.
Data warehouses remain a strong choice for organizations that prioritize structured reporting and governed analytics environments.
Final Decision Framework
In simple terms:
- Choose a Data Warehouse when your primary focus is structured reporting, BI dashboards, and governed enterprise analytics.
- Choose a Data Lakehouse when your organization needs to support large-scale data processing, diverse data types, and AI-driven workloads.
Many modern enterprises adopt a lakehouse-first architecture, where the lakehouse acts as the central data platform and curated datasets are optimized for BI and reporting.
TLDR: Data Warehouse vs Data Lakehouse
If you need a quick summary of data warehouse vs data lakehouse, here are the key takeaways:
- A data warehouse is designed for structured data, reporting, and business intelligence. It provides reliable performance for dashboards, financial reporting, and operational analytics.
- A data lakehouse combines the low-cost storage and flexibility of data lakes with the governance and performance of data warehouses.
- Data warehouses work best when organizations mainly deal with structured data and BI workloads.
- Data lakehouses are better suited for large-scale data environments that include structured, semi-structured, and unstructured data, especially when supporting AI, machine learning, and advanced analytics.
- Many modern enterprises adopt a hybrid or lakehouse-first architecture, where raw and large-scale data is stored in the lakehouse while curated datasets power BI tools and reporting systems.
FAQs: Data Warehouse vs Data Lakehouse
1. What is the main difference between a data warehouse and a data lakehouse?
The main difference between a data warehouse and a data lakehouse is the type of data they support and how they process it. A data warehouse is optimized for structured data and reporting, while a data lakehouse can handle structured, semi-structured, and unstructured data while supporting analytics, machine learning, and large-scale data processing.
2. Is a data lakehouse replacing a data warehouse?
A data lakehouse does not always replace a data warehouse. Instead, many organizations use both architectures together. A lakehouse stores and processes large volumes of diverse data, while the warehouse delivers curated datasets optimized for business intelligence and reporting.
3. When should a company use a data warehouse instead of a lakehouse?
A company should choose a data warehouse when its primary use case is business intelligence, dashboards, financial reporting, and structured analytics with strong governance and consistent data models.
4. Why are companies adopting data lakehouse architectures?
Companies are adopting data lakehouse architectures because they provide scalable storage, support multiple data types, and enable advanced analytics and AI workloads on a unified platform.
5. Which is better for AI and machine learning: data warehouse or lakehouse?
A data lakehouse is generally better suited for AI and machine learning workloads because it allows data scientists to work with large volumes of raw and diverse datasets while maintaining governance and performance through modern table formats.