


Data Pipeline vs ETL: Which One Does Your Data Platform Actually Need?
If you ask five data engineers to explain data pipeline vs ETL, you may get five different answers.
Some consider ETL a type of data pipeline. Others believe data pipelines are replacing traditional ETL processes. And in many organizations, the two terms are used interchangeably, which often leads to confusion when designing data architectures.
In reality, data pipelines and ETL serve different roles in the data ecosystem. ETL focuses on extracting, transforming, and loading structured data into analytics systems. Data pipelines provide the broader infrastructure that moves data between applications, platforms, and storage systems.
Understanding the distinction between data pipeline vs ETL is critical for building efficient, scalable, and modern data platforms. This guide explains the key differences, architecture patterns, and when to use each approach.
TL;DR
The difference between data pipeline vs ETL lies in their scope and purpose.
A data pipeline is the broader system that moves data from one place to another. It manages the flow of data between sources, processing systems, and destinations, and can support both batch and real time data movement.
ETL (Extract, Transform, Load) is a specific process used to extract data from multiple sources, transform it into a structured format, and load it into a target system such as a data warehouse.
In simple terms, ETL is often one process within a larger data pipeline. Modern data architectures typically use both together to ensure data moves efficiently and is properly prepared for analytics, reporting, and AI applications.
What is a Data Pipeline?
A data pipeline is a system that moves data from one or more sources to a destination where it can be stored, processed, or analyzed. It automates the flow of data across systems, ensuring that information is consistently collected, processed, and delivered without manual intervention.
Data pipelines are a fundamental component of modern data architecture because organizations rely on multiple data sources such as applications, databases, APIs, IoT devices, and cloud platforms. A data pipeline ensures that this data flows smoothly into destinations like data warehouses, data lakes, analytics platforms, or machine learning systems.
Unlike traditional batch processes, modern data pipelines can handle both batch data processing and real time data streaming, allowing businesses to analyze and act on data faster.
Key Components of a Data Pipeline
A typical data pipeline consists of several stages that move and prepare data for downstream systems.
- Data Sources: These are the systems where data originates. Sources can include operational databases, SaaS applications, APIs, event streams, logs, or IoT devices.
- Data Ingestion: Data is collected from source systems and brought into the pipeline. Ingestion can occur in batches at scheduled intervals or continuously through streaming.
- Data Processing or Transformation: In this stage, data may be cleaned, enriched, filtered, or transformed to make it usable for analytics or applications.
- Data Storage or Destination: The processed data is delivered to a target system such as a data warehouse, data lake, analytics platform, or operational system.
How a Data Pipeline Works
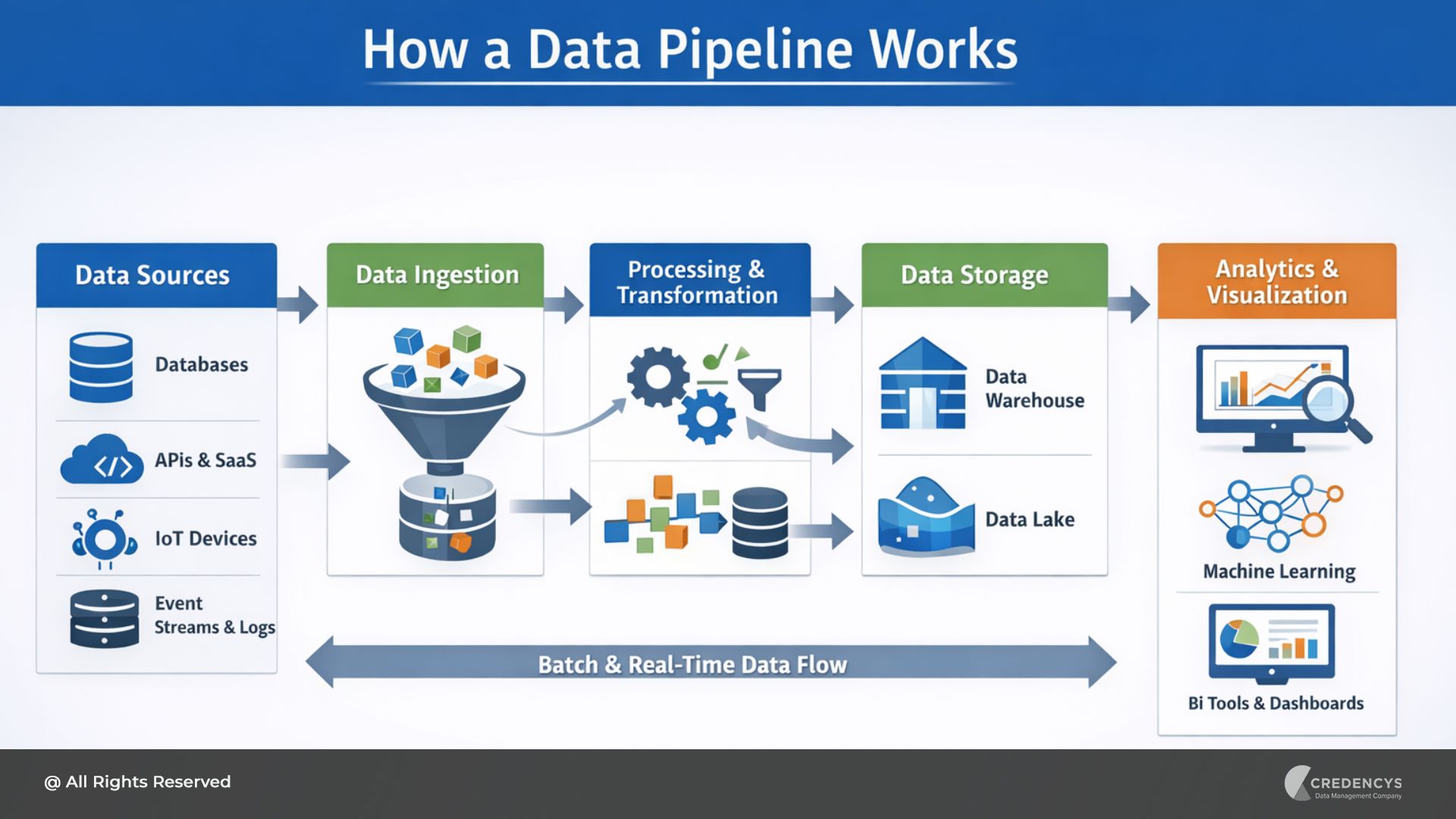
In a typical data pipeline architecture, data flows through several stages:
- Data is generated in source systems such as applications, databases, or external APIs.
- The pipeline ingests this data through connectors or ingestion tools.
- Processing systems clean, validate, or transform the data if needed.
- The prepared data is stored in platforms like data lakes or data warehouses.
- Analytics tools, dashboards, or machine learning models use the data for insights and decision making.
What is ETL?
ETL stands for Extract, Transform, and Load. It is a data integration process used to collect data from multiple sources, transform it into a structured and usable format, and load it into a target system such as a data warehouse or analytics platform.
ETL has been a core component of traditional data warehousing for decades. It helps organizations consolidate data from different systems and prepare it for reporting, business intelligence, and analytics.
The goal of ETL is to ensure that data stored in analytical systems is clean, consistent, and structured for accurate insights.
The Three Stages of ETL
The ETL process consists of three main steps.
1. Extract
In the extraction stage, data is collected from various source systems. These sources can include databases, enterprise applications, CRM platforms, ERP systems, APIs, and log files.
The extracted data may exist in different formats and structures, which is why it needs further processing before it can be used.
2. Transform
During the transformation stage, the extracted data is cleaned, standardized, and prepared for analysis. This may involve several operations such as:
- Removing duplicates and errors
- Converting data formats
- Applying business rules
- Aggregating or filtering data
- Enriching datasets with additional information
This step ensures the data is reliable and consistent for analytical workloads.
3. Load
In the final stage, the transformed data is loaded into a target destination. Common destinations include data warehouses, data marts, and analytics systems where the data can be queried and analyzed by business users.
ETL Process Flow
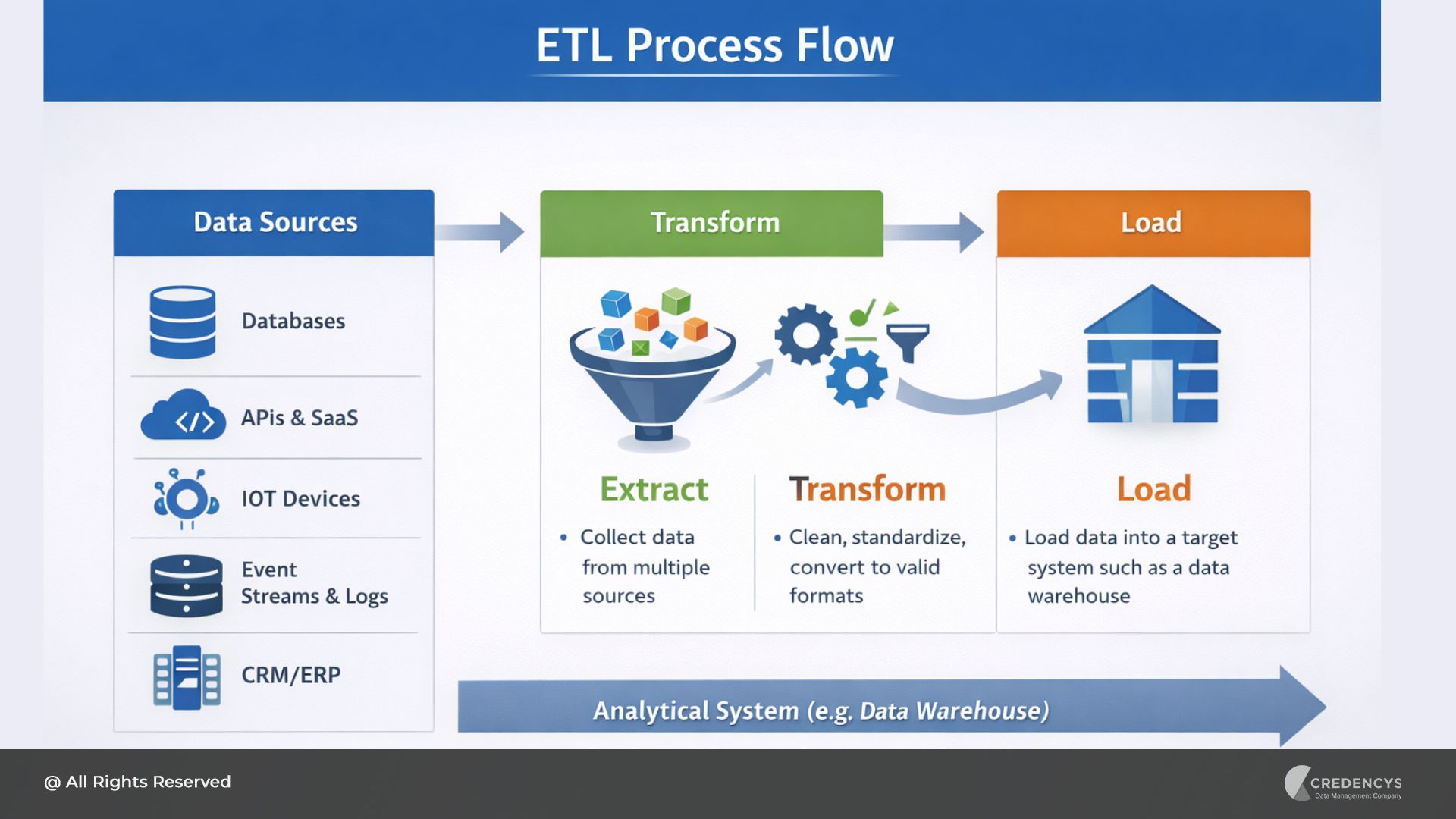
A typical ETL workflow follows this sequence:
- Data is extracted from multiple operational systems.
- The data is transformed to ensure quality, consistency, and compatibility with analytical systems.
- The processed data is loaded into a centralized storage platform such as a data warehouse.
Once loaded, the data becomes available for reporting, dashboards, and advanced analytics.
Why ETL is Important
ETL plays a crucial role in enabling organizations to build reliable analytics environments. Key benefits include:
- Data Consistency: ETL standardizes data coming from different systems, ensuring consistent formats and definitions.
- Improved Data Quality: Transformation processes clean and validate data before it enters analytical systems.
- Centralized Analytics: ETL consolidates data into a single destination such as a data warehouse, making it easier for teams to analyze information.
- Support for Business Intelligence: Clean and structured datasets enable accurate reporting, dashboards, and data driven decision making.
Data Pipeline vs ETL: Key Differences
Although data pipelines and ETL are closely related, they are not the same. ETL is a specific process used within data integration workflows, while a data pipeline represents the broader infrastructure responsible for moving data across systems.
Understanding the distinction between data pipeline vs ETL helps organizations design more efficient and scalable data architectures.
Below is a comparison of the key differences.
| Aspect | Data Pipeline | ETL |
|---|---|---|
| Definition | A system that moves data from one system to another | A process that extracts, transforms, and loads data into a destination |
| Scope | Broad concept that manages data movement across systems | A specific type of data integration process |
| Transformation | May or may not include data transformation | Always includes transformation before loading |
| Use Cases | Data integration, streaming data, real-time analytics, machine learning pipelines | Data warehousing, reporting, business intelligence |
| Processing Mode | Supports both batch processing and real-time data streaming | Traditionally batch-based |
| Flexibility | Can move structured, semi-structured, and unstructured data | Primarily designed for structured data |
Key Takeaway
The easiest way to understand data pipeline vs ETL is to view ETL as a type of workflow that can exist inside a data pipeline.
A data pipeline focuses on moving data efficiently across systems, while ETL focuses on transforming data so it can be used for analytics and reporting.
In modern data architectures, organizations often use data pipelines to orchestrate multiple processes, including ETL, ELT, streaming ingestion, and real time data processing.
When to Use Data Pipelines vs ETL
Choosing between a data pipeline and ETL depends on the type of data architecture an organization is building and the specific use case it needs to support. While ETL focuses on preparing data for analytics systems, data pipelines provide the broader infrastructure for moving data across platforms and applications.
Understanding when to use each approach helps organizations design efficient and scalable data systems.
When to Use a Data Pipeline
Data pipelines are ideal when organizations need to move data continuously across multiple systems and support modern data workloads.
Common scenarios include:
1. Real Time Data Processing
Organizations that rely on real time insights, such as fraud detection, recommendation engines, or monitoring systems, use data pipelines to stream data continuously.
2. Multiple Data Sources and Destinations
When data needs to flow between many systems such as applications, APIs, cloud platforms, and data lakes, pipelines help orchestrate the movement efficiently.
3. Machine Learning and AI Workloads
Data pipelines enable automated data delivery for training models, running predictions, and updating AI systems with fresh data.
4. Event Driven Architectures
Modern applications often generate event streams that must be processed and delivered in near real time, which is best handled through pipelines.
When to Use ETL
ETL is best suited for structured data integration and preparing data for analytics and reporting environments.
Typical scenarios include:
1. Data Warehousing
Organizations use ETL to extract data from operational systems, transform it into consistent formats, and load it into a centralized data warehouse.
2. Business Intelligence and Reporting
ETL ensures that data used for dashboards and reports is clean, standardized, and reliable.
3. Data Consolidation
When data from multiple systems must be combined into a single analytical environment, ETL processes help ensure consistency.
4. Historical Data Analysis
ETL workflows are often used to process historical datasets that are loaded periodically into analytics systems.
The Modern Approach
In modern data architectures, organizations rarely treat data pipelines vs ETL as competing approaches. Instead, ETL is often implemented within a broader data pipeline architecture.
For example, a data pipeline may ingest data from applications, process it through ETL transformations, and then deliver it to a data warehouse or analytics platform.
This combination allows organizations to build scalable data platforms that support both operational data movement and advanced analytics.
Data Pipeline vs ETL in Modern Data Architectures
As data ecosystems evolve, the discussion around data pipeline vs ETL has become more relevant for organizations building modern data platforms. Traditional ETL processes were designed primarily for structured data and batch processing in data warehouses. However, modern businesses generate data from a wide range of sources, including cloud applications, APIs, mobile platforms, and connected devices.
To handle these growing data demands, organizations are adopting modern data architectures that rely heavily on scalable data pipelines.
1. Shift from Batch Processing to Continuous Data Flow
Traditional ETL workflows typically operate in scheduled batches. Data is extracted from source systems, transformed, and then loaded into a data warehouse at specific intervals such as hourly or daily.
Modern data pipelines support both batch and real time data processing, enabling organizations to ingest and process data continuously. This capability is essential for use cases such as fraud detection, recommendation engines, real time analytics, and operational monitoring.
2. Rise of Cloud Data Platforms
Cloud data platforms have significantly changed how organizations manage and process data. Instead of relying solely on on premises data warehouses, companies now use cloud based platforms that support flexible and scalable data pipelines.
These platforms enable organizations to ingest large volumes of structured and unstructured data while supporting advanced analytics and machine learning workloads.
3. From ETL to ELT
Another major shift in modern data architecture is the transition from ETL to ELT (Extract, Load, Transform).
In this approach, data is first loaded into a data warehouse or data lake and then transformed within the platform itself. Cloud data warehouses provide the computational power needed to perform transformations directly within the storage layer.
This shift allows organizations to process larger datasets and reduce the complexity of traditional ETL workflows.
4. Building a Unified Data Ecosystem
Today, organizations rarely rely on a single data integration method. Instead, they build comprehensive data ecosystems that include:
- Data pipelines for continuous data movement
- ETL or ELT processes for data transformation
- Data lakes and warehouses for storage
- Analytics and machine learning platforms for insights
In this context, the debate around data pipeline vs ETL becomes less about choosing one over the other and more about understanding how both approaches work together to support modern data platforms.
Key Takeaways: Data Pipeline vs ETL
Understanding data pipeline vs ETL is important for designing efficient and scalable data architectures. While the terms are sometimes used interchangeably, they represent different concepts within the data ecosystem.
Here are the key points to remember.
- Data pipelines are broader systems: A data pipeline is responsible for moving data between systems. It manages the entire flow of data from sources to destinations and may include ingestion, processing, and delivery stages.
- ETL is a specific data integration process: ETL focuses on extracting data from sources, transforming it into a usable format, and loading it into a target system such as a data warehouse.
- Data pipelines can include ETL processes: In many architectures, ETL workflows operate inside a data pipeline. The pipeline orchestrates how data moves, while ETL ensures the data is properly prepared for analytics.
- Modern architectures combine multiple approaches: Today’s data platforms often use a mix of data pipelines, ETL or ELT processes, and cloud data platforms to support analytics, AI, and real time decision making.
- The right approach depends on your use case: Organizations that need continuous data movement and real time processing rely heavily on data pipelines. Businesses focused on structured analytics and reporting environments commonly use ETL.
Data Pipeline vs ETL FAQs
1. What is the difference between a data pipeline and ETL?
The difference between data pipeline vs ETL lies in their scope. A data pipeline is a broader system that moves data from one system to another, which may or may not include transformation. ETL (Extract, Transform, Load) is a specific data integration process that extracts data from sources, transforms it into a usable format, and loads it into a destination such as a data warehouse.
2. Is ETL a type of data pipeline?
Yes, ETL can be considered a type of data pipeline process. A data pipeline manages the overall movement of data across systems, while ETL focuses specifically on extracting, transforming, and loading data for analytics or reporting. In modern architectures, ETL workflows often run as part of larger data pipelines.
3. Do modern data architectures still use ETL?
Yes, ETL is still widely used in modern data architectures, especially for data warehousing, reporting, and business intelligence. However, organizations increasingly combine ETL with data pipelines and ELT approaches to support real time analytics, machine learning, and large scale cloud data platforms.





Tags: