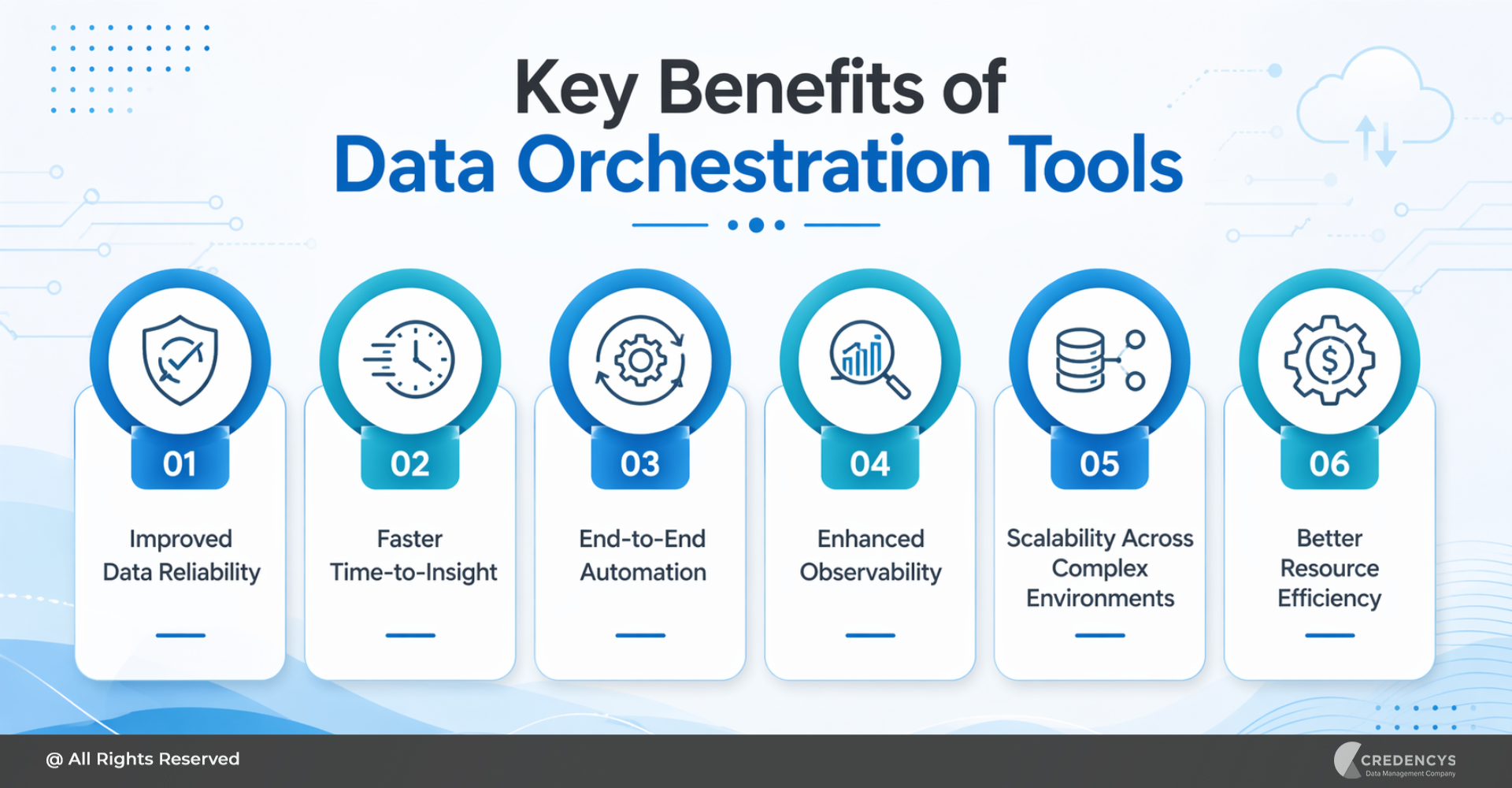
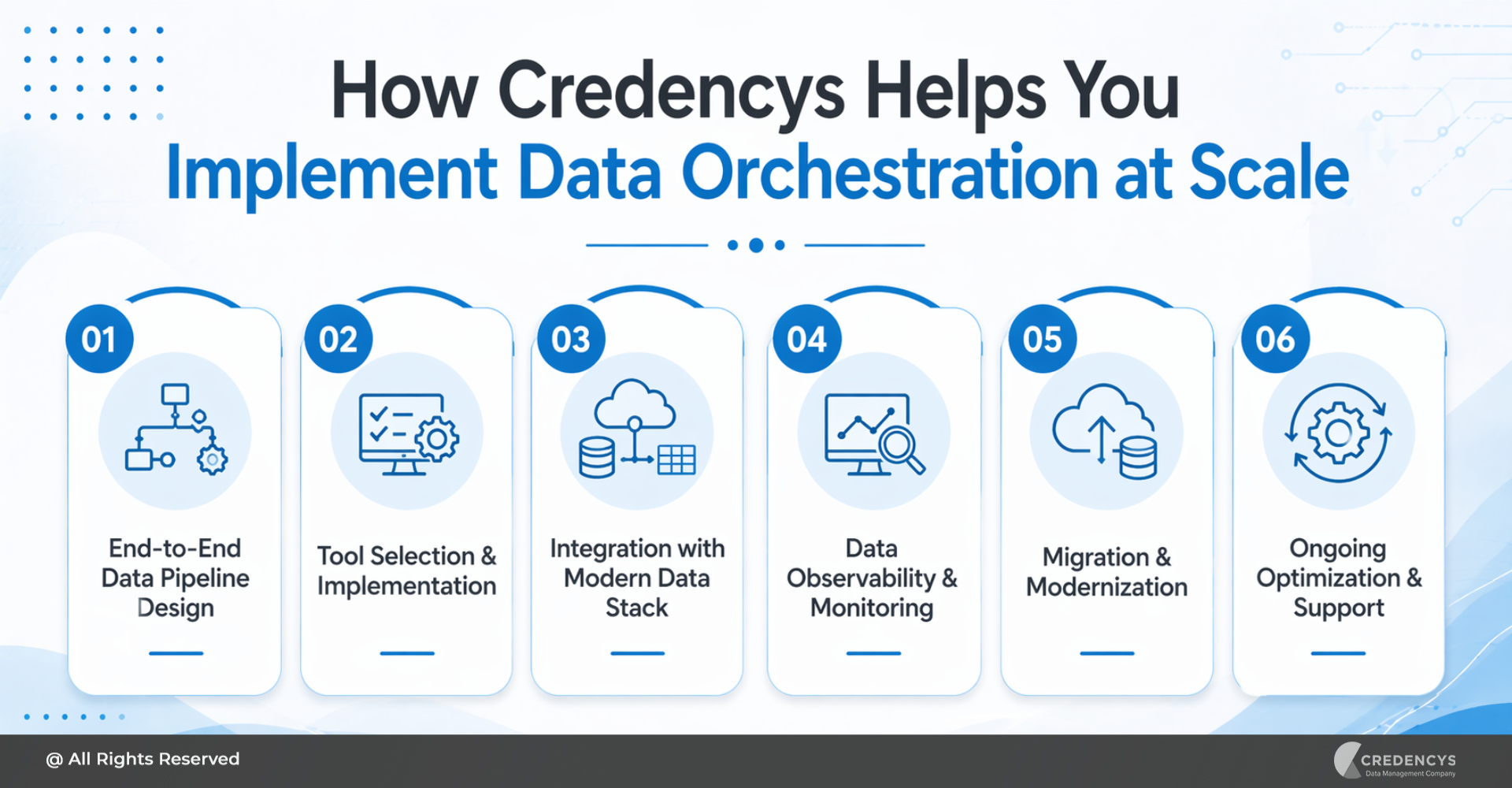
Data is no longer just a byproduct of business operations; it’s the foundation of competitive advantage. Over the past few years, organizations have rapidly adopted modern data platforms to unify analytics, AI, and real-time decision-making.
At the center of this shift is Databricks and the lakehouse architecture, enabling businesses to break down silos and accelerate innovation. But while the technology is powerful, the implementation is not simple.
From migrating legacy systems to building scalable AI pipelines, most organizations struggle with execution. That’s where Databricks consulting companies come in.
The right partner can help you unlock faster time-to-value, reduce risk, and maximize ROI. The wrong one can lead to delays, cost overruns, and underperforming data initiatives.
In this guide, we’ll cover:
- Why businesses need Databricks consulting partners in 2026
- How to evaluate and choose the right partner
- A curated list of top Databricks consulting companies
- A comparison table to simplify your decision
Why Businesses Need Databricks Consulting Partners in 2026
The Challenge: Increasing Data Complexity
Modern data ecosystems are more complex than ever. Organizations are dealing with:
- Multiple data sources (structured, semi-structured, unstructured)
- Real-time and batch processing requirements
- Integration with AI/ML models and business applications
Without the right expertise, managing this complexity becomes overwhelming.
The Talent Gap
There is a growing shortage of professionals skilled in Databricks, Apache Spark, and advanced data engineering. Hiring and retaining such talent in-house is both expensive and time-consuming.
The Need for Faster Time-to-Value
Businesses can’t afford long implementation cycles. They need to:
- Launch data platforms quickly
- Deliver insights faster
- Scale AI initiatives efficiently
Databricks consulting partners bring proven frameworks, accelerators, and expertise to speed up execution.
Key Use Cases for Databricks Consulting
Databricks consulting companies don’t just implement technology; they help organizations unlock business value from data at scale. Below are the most impactful use cases in 2026:
1. Data Lakehouse Implementation
Many organizations struggle with fragmented data across warehouses and lakes. Databricks consultants help design and implement a lakehouse architecture that:
- Unifies data engineering, analytics, and AI
- Eliminates data silos
- Improves data accessibility and governance
2. Hadoop & Legacy Data Warehouse Migration
Legacy systems such as Hadoop and traditional data warehouses are costly, rigid, and difficult to scale. Consulting partners:
- Assess existing architecture
- Design migration roadmaps
- Execute seamless transitions to Databricks
3. AI/ML Pipeline Development & MLOps
Building models is easy, but scaling them is not. Databricks consulting companies help:
- Develop end-to-end ML pipelines
- Implement MLOps frameworks
- Automate model deployment and monitoring
4. Real-Time & Streaming Analytics
Modern businesses require real-time insights, especially in retail, logistics, and finance. Consultants enable:
- Streaming data pipelines
- Real-time dashboards
- Event-driven architectures
5. Data Engineering & Pipeline Optimization
Poorly designed pipelines lead to delays, failures, and high costs. Databricks experts:
- Optimize Spark workloads
- Improve pipeline reliability
- Reduce compute costs

How We Selected the Top Databricks Consulting Companies
To ensure this list is credible and actionable, we used a multi-dimensional evaluation framework aligned with how real buyers make decisions.
1. Databricks Certifications & Partner Status
We prioritized companies that are official Databricks partners with certified professionals. Certified partners have validated expertise and access to the latest platform capabilities.
2. Industry-Specific Expertise
Not all consulting firms understand your domain. We evaluated:
- Retail & eCommerce experience
- Manufacturing & supply chain expertise
- CPG and data-heavy industry exposure
Industry context accelerates implementation and improves outcomes
3. End-to-End Capabilities
Top firms don’t just implement, they transform. We looked for:
- Data engineering
- Data architecture
- AI/ML capabilities
- Analytics and BI
You need a partner who can handle the entire data lifecycle, not just one piece.
4. Proven Client Success
We analyzed:
- Case studies
- Measurable outcomes (ROI, performance gains)
- Real-world implementations
Execution capability matters more than marketing claims.
5. Scalability & Engagement Flexibility
Different companies have different needs. We assessed:
- Ability to serve mid-market vs enterprise
- Flexible engagement models
- Global vs regional delivery
The right partner should scale with your business, not constrain it.
Top Databricks Consulting Companies in 2026
Below is a curated list of leading Databricks consulting companies that stand out in 2026.
1. Credencys Solutions
A fast-growing Databricks consulting partner focused on data modernization and AI transformation. Known for its strong presence in retail and eCommerce, Credencys combines deep technical expertise with an agile delivery model.
Credencys offers a balanced approach combining deep technical expertise with agility and cost efficiency, making it an ideal alternative to large system integrators.
Key Strengths:
- Strong expertise in retail, eCommerce, and supply chain
- End-to-end capabilities across data engineering and AI/ML
- Proven experience in lakehouse architecture
Best For:
- Mid-market and scaling enterprises
2. Tiger Analytics
A leading analytics and AI firm specializing in data science-driven decision-making. Strong in retail and CPG, with a focus on delivering business insights through advanced analytics.
Key Strengths:
- Strong presence in retail and CPG
- Advanced analytics and AI capabilities
Best For:
- Enterprises looking for AI-driven decision intelligence
3. Tredence
A data science and AI consulting company focused on customer analytics and business intelligence. Known for helping enterprises turn data into actionable insights.
Key Strengths:
- Customer analytics expertise
- Strong AI and machine learning focus
Best For:
Organizations focused on customer-centric analytics
4. Slalom
A business and technology consulting firm offering strategy-to-execution services. Strong in aligning business goals with technical implementations.
Key Strengths:
- Strong client collaboration model
- End-to-end delivery capabilities
Best For:
Companies looking for both strategy and execution
5. Sigmoid
A data engineering-focused company specializing in cloud-native analytics and real-time data processing. Ideal for organizations needing a scalable data infrastructure.
Key Strengths:
- Real-time data processing
- Scalable data pipelines
Best For:
Organizations needing advanced data engineering solutions
Comparison Table: Top Databricks Consulting Companies
| Company | Best For | Key Strength | Industry Focus | Engagement Size |
|---|---|---|---|---|
| Credencys | Mid-market transformation | Data + AI + retail expertise | Retail, CPG | Mid-market |
| Tiger Analytics | AI-led analytics | Advanced analytics | Retail, CPG | Enterprise |
| Tredence | Customer analytics | AI + data science | Retail, BFSI | Enterprise |
| Slalom | Strategy + implementation | Business + tech consulting | Multi-industry | Mid-large |
| Sigmoid | Data engineering | Real-time analytics | Tech, retail | Mid-large |
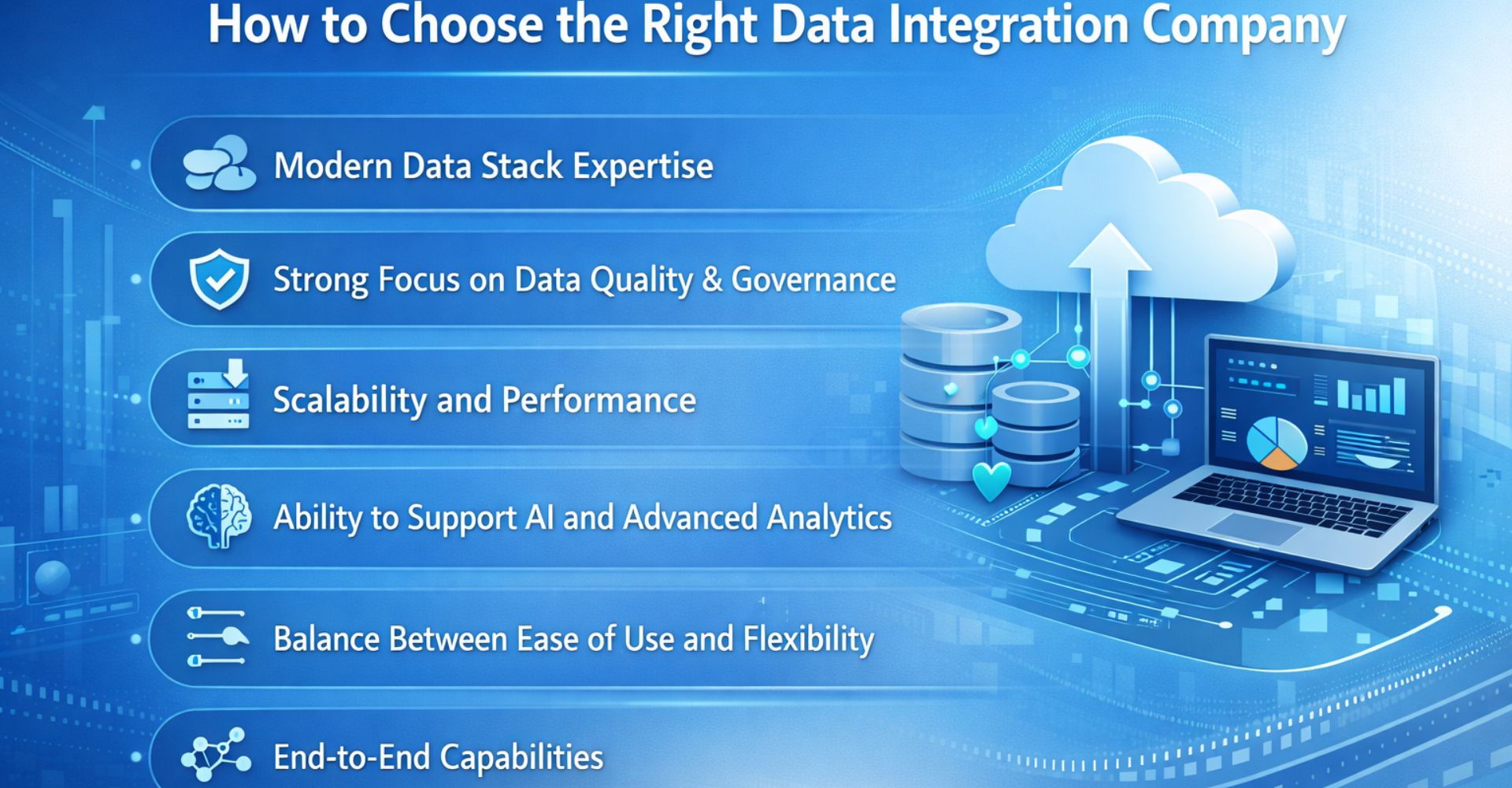
How to Choose the Right Databricks Consulting Company
Selecting the right Databricks consulting partner is a strategic decision that can significantly impact your data and AI success. Beyond technical expertise, the ideal partner should align with your business goals, industry needs, and long-term scalability plans.
Here’s how to evaluate your options effectively:
1. Verify Certifications and Partner Status
Start by checking whether the consulting company is an official Databricks partner with certified professionals on their team. Certifications indicate that the team has undergone formal training and understands the platform’s best practices.
A recognized partner is also more likely to stay up to date with the latest Databricks features and innovations. This ensures your implementation is future-ready and aligned with platform advancements.
2. Look for Relevant Industry Experience
Industry expertise plays a crucial role in successful implementation. A partner familiar with your domain can better understand your data challenges, compliance requirements, and business objectives.
For example, data use cases in retail differ significantly from those in manufacturing or finance. Choosing a partner with proven experience in your industry can accelerate deployment and improve outcomes.
3. Evaluate End-to-End Capabilities
Databricks projects often require more than just data engineering. From data ingestion and transformation to AI/ML deployment and analytics, the right partner should cover the entire lifecycle.
Working with a full-service provider reduces the need to manage multiple vendors. It also ensures better coordination, faster execution, and a more cohesive data strategy.
4. Assess Proven Results and Client Success
Instead of relying solely on marketing claims, ask for case studies, client references, and measurable results. Look for evidence of successful implementations with tangible business impact.
Metrics such as reduced costs, improved performance, or increased revenue can give you confidence in the partner’s capabilities. Real-world success stories are often the best indicators of reliability.
5. Consider Scalability and Cost Alignment
Your chosen partner should be able to scale with your business as your data needs grow. Evaluate their engagement models, team structure, and ability to handle larger or more complex projects over time.
At the same time, ensure their pricing aligns with your budget and expected ROI. A partner that offers flexibility and long-term value will be more beneficial than one that only meets short-term needs.

Why Credencys Stands Out as a Databricks Consulting Partner
Choosing the right partner isn’t just about technical skills; it’s about alignment with your business goals. Credencys stands out by offering:
- Industry Focus: Deep expertise in retail, eCommerce, and supply chain
- AI-Driven Approach: Strong capabilities in machine learning and advanced analytics
- Agile Execution: Faster delivery compared to large system integrators
- Cost Efficiency: High-quality services without enterprise-level pricing
This combination makes Credencys a strong choice for organizations looking to modernize their data platforms and scale AI initiatives effectively.
Conclusion: The Right Partner Can Make or Break Your Data Strategy
Databricks has become a cornerstone of modern data and AI strategies. But the platform alone isn’t enough; success depends on how well it’s implemented and scaled.
The right consulting partner can:
- Accelerate your data transformation journey
- Reduce risk and complexity
- Deliver measurable business outcomes
On the other hand, the wrong choice can slow you down and limit your ROI.