Machine learning is no longer experimental; it’s mission-critical. Yet, most enterprises still struggle to move models from experimentation to production.
Despite heavy investments in AI, only a small percentage of models deliver real business value. This is where MLOps (Machine Learning Operations) becomes essential.
And more importantly, choosing the right MLOps company can make or break your AI success. In this blog, we’ll explore:
- The top MLOps companies in 2026
- What makes them stand out
- How to choose the right partner for your business
Why MLOps Is Critical for Enterprises in 2026
Building ML models is just the beginning. The real challenge lies in:
- Deploying models reliably
- Monitoring performance over time
- Managing data and model drift
- Ensuring governance and compliance
Without MLOps, organizations face:
- Fragmented workflows
- Delayed deployments
- Inconsistent model performance
- High operational costs
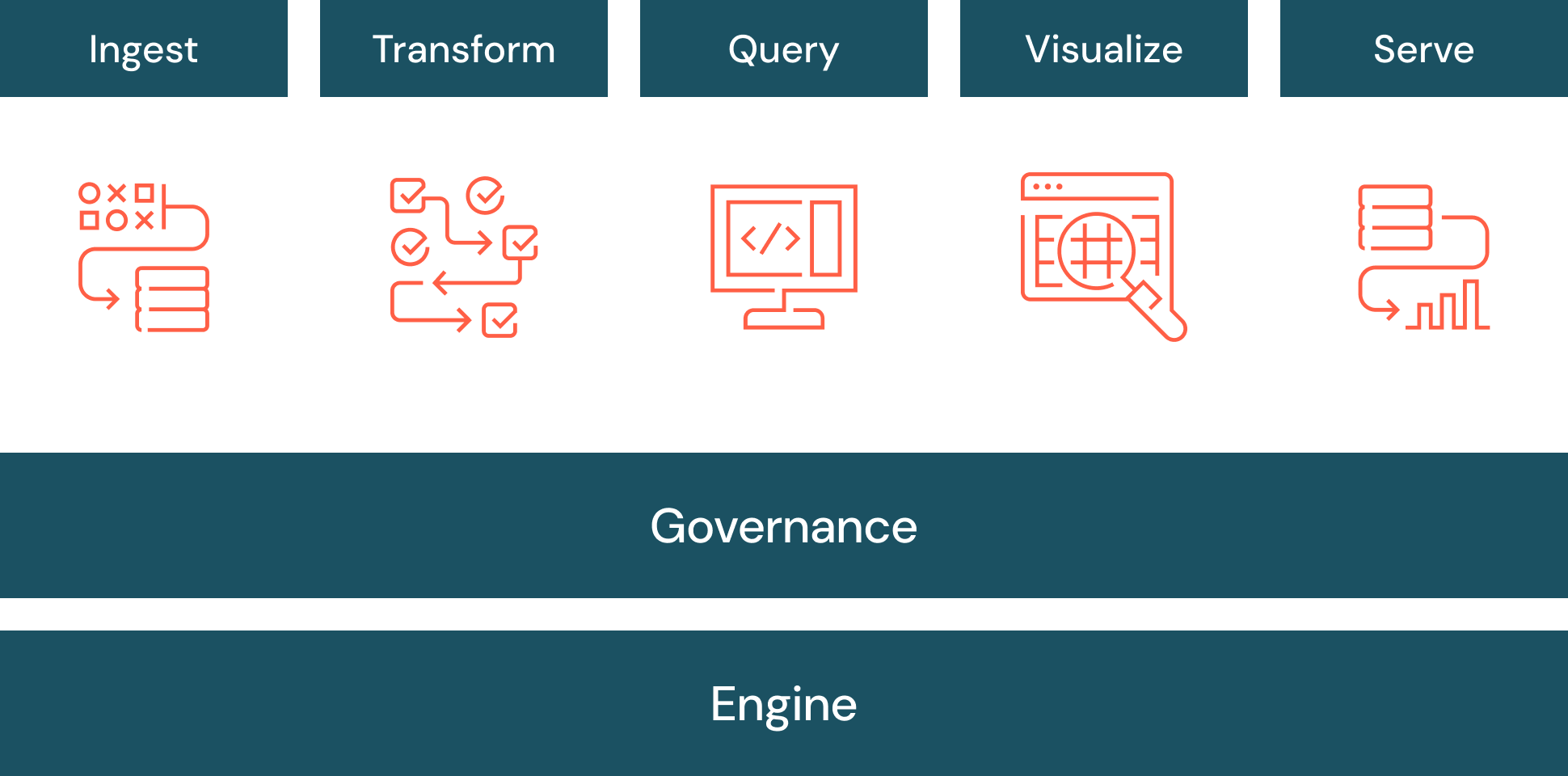
MLOps bridges the gap between data science and production systems, enabling scalable, repeatable, and governed AI operations.
What to Look for in an MLOps Company
Choosing an MLOps partner is a strategic one that directly impacts how effectively your organization can scale AI initiatives. The right partner should not only understand machine learning but also how to operationalize it across complex enterprise environments.
Here are the key factors to evaluate in detail:
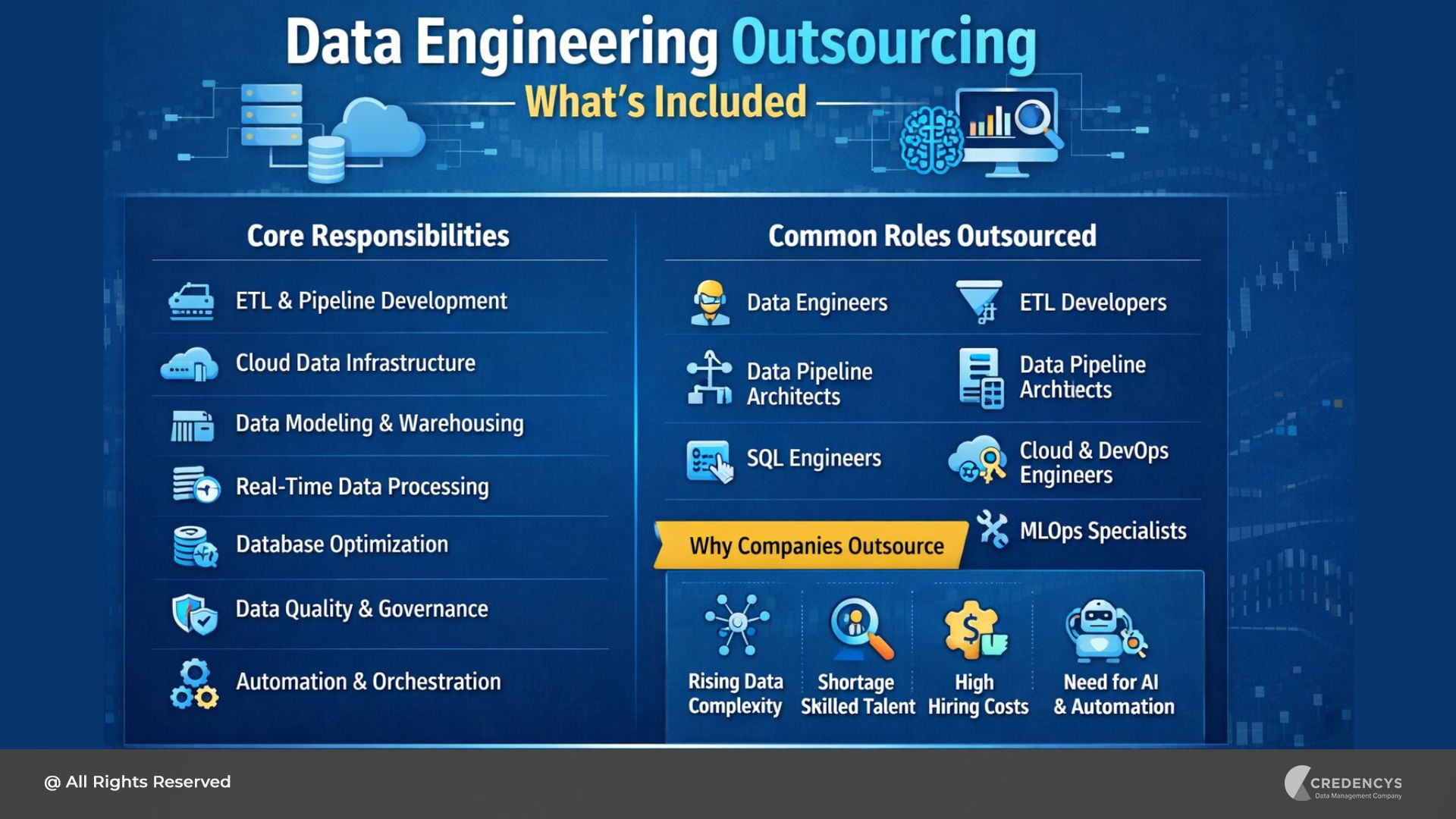
1. End-to-End MLOps Capabilities
Many vendors claim MLOps expertise but only specialize in isolated parts of the lifecycle, such as model development or infrastructure setup. A strong MLOps company should support the entire lifecycle, including:
- Data ingestion and preprocessing
- Feature engineering and versioning
- Model training and experimentation
- Model deployment (batch and real-time)
- Continuous monitoring and retraining
This end-to-end ownership ensures there are no gaps between stages, reducing friction and accelerating time-to-production. It also eliminates the need to coordinate multiple vendors, thereby reducing inefficiencies.
2. Deep Platform and Ecosystem Expertise
Modern MLOps is heavily dependent on tools and platforms. However, simply knowing tools isn’t enough; your partner should have hands-on experience integrating and optimizing them within enterprise ecosystems.
Look for expertise in:
- Unified platforms like Databricks (Lakehouse architecture)
- Orchestration tools like Kubernetes and Airflow
- ML lifecycle tools such as MLflow or Kubeflow
- Cloud ecosystems (AWS, Azure, GCP)
More importantly, they should know when to use what and how to design a cohesive architecture rather than a fragmented toolchain.
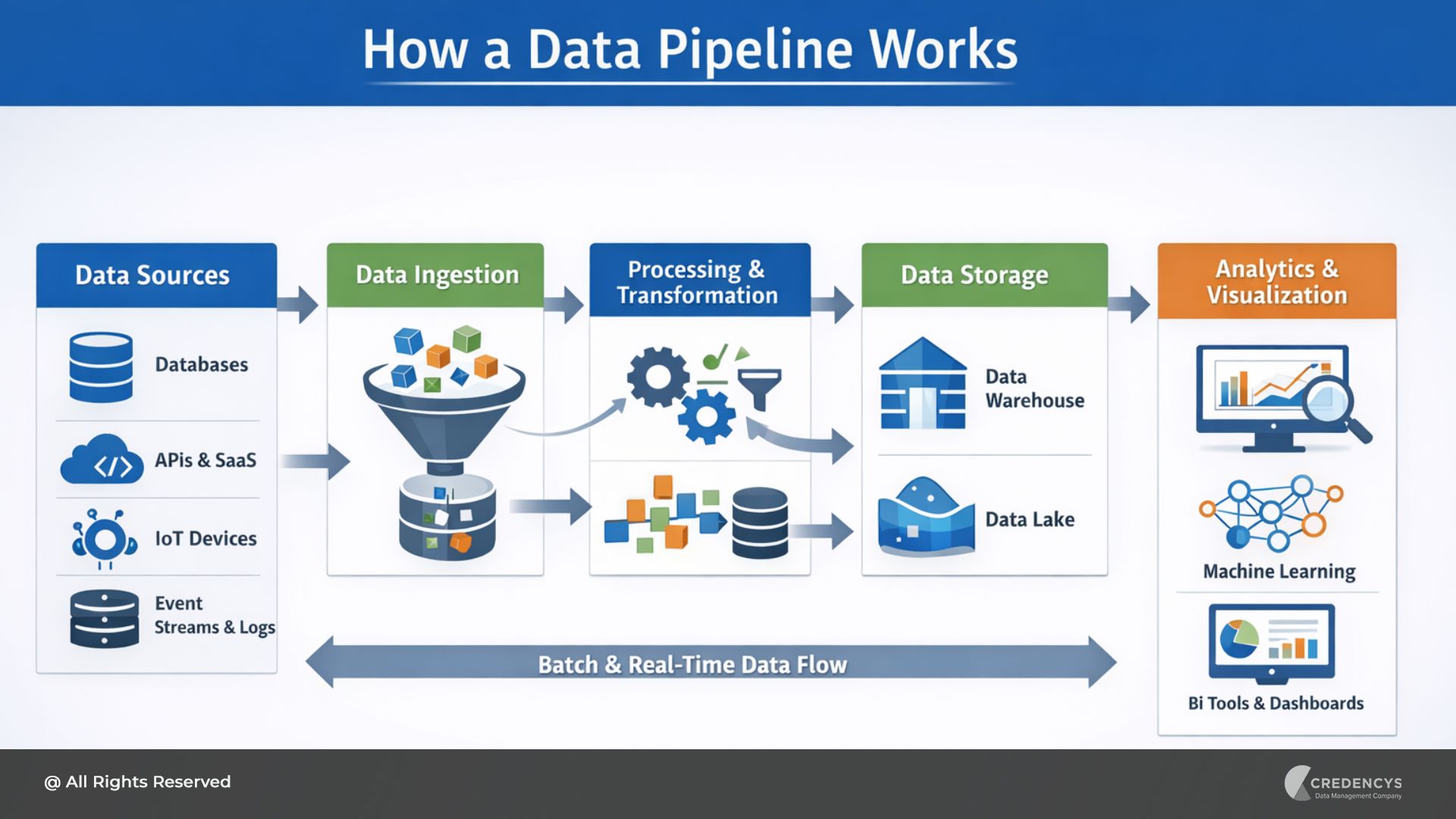
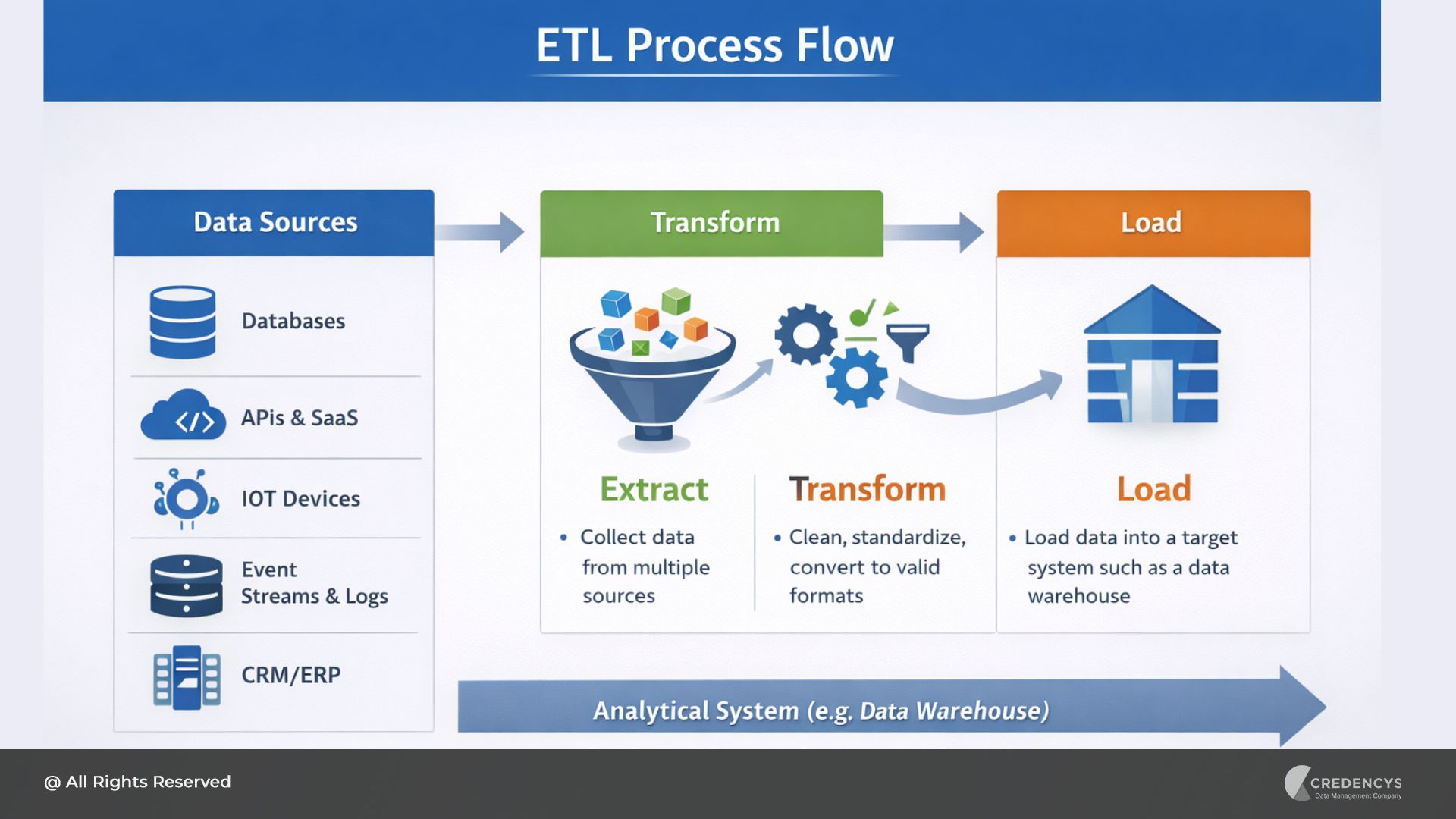
3. Strong Data Engineering Foundation
MLOps is only as good as the data that powers it. A capable MLOps company must have strong data engineering capabilities, including:
- Building scalable data pipelines
- Ensuring data quality and consistency
- Managing large-scale structured and unstructured data
- Supporting real-time and batch processing
Without this foundation, even the most advanced ML models will fail in production due to unreliable data.
4. Industry-Specific Experience
AI is not one-size-fits-all. The challenges faced in retail (e.g., demand forecasting), manufacturing (e.g., predictive maintenance), or supply chain (e.g., inventory optimization) are fundamentally different.
An experienced MLOps partner brings:
- Pre-built accelerators and frameworks
- Understanding of domain-specific KPIs
- Faster implementation cycles
This reduces experimentation time and increases the likelihood of success.
5. Scalability, Automation, and Performance Optimization
As organizations mature, they move from managing a few models to hundreds or even thousands. Your MLOps partner should design systems that:
- Automatically scale infrastructure based on demand
- Enable CI/CD pipelines for ML models
- Reduce manual intervention through automation
- Optimize performance and cost across environments
This ensures your AI initiatives remain sustainable as they grow.
6. Governance, Security, and Compliance
With increasing regulations around AI, governance is no longer optional. A mature MLOps company should provide:
- Model explainability and transparency
- Version control for models and datasets
- Audit trails for compliance
- Role-based access controls and security frameworks
This is especially critical for enterprises operating in regulated industries or across multiple geographies.

Top MLOps Companies in 2026
Here are the top MLOps service providers helping enterprises operationalize AI at scale:
1. Credencys Solutions
Credencys stands out as a strategic MLOps partner for enterprises looking to scale AI initiatives, not just implement tools. With strong expertise in Databricks and modern data architectures, Credencys helps organizations move from fragmented ML efforts to fully operationalized AI ecosystems.
Key Strengths
- End-to-end MLOps implementation (data → model → deployment → monitoring)
- Deep expertise in Data Engineering + AI + Lakehouse architecture
- Custom ML pipelines tailored for retail, CPG, and manufacturing
- Strong focus on governance, model monitoring, and optimization
What Sets Them Apart
Credencys doesn’t just deploy models; they build scalable AI foundations that align with business outcomes.
Best for: End-to-end MLOps + Data Engineering + AI transformation
2. Turing
Turing provides enterprises with access to vetted remote AI engineers and MLOps specialists.
Key Strengths
- Large pool of AI/ML talent
- Flexible engagement models
- Quick team scaling
Best for: Access to global AI/ML talent and MLOps engineers
Limitations
- More talent-focused than full lifecycle MLOps consulting
- Limited strategic transformation capabilities
3. Markovate
Markovate focuses on building AI-powered applications and integrating MLOps practices into product development.
Key Strengths
- Strong AI product engineering
- MLOps integration for startups and mid-market
- Focus on innovation and rapid development
Best for: AI product development with MLOps integration
Limitations
- Less focus on large-scale enterprise transformation
- Limited depth in data engineering ecosystems
4. Intellias
Intellias brings strong engineering capabilities and supports MLOps within broader digital transformation initiatives.
Key Strengths
- Enterprise IT and engineering expertise
- Scalable architecture design
- Strong delivery capabilities
Best for: Enterprise-grade digital transformation with MLOps
Limitations: MLOps is part of broader services, not always the core focus
5. Accenture
Accenture is a global consulting giant offering comprehensive AI and MLOps services.
Key Strengths
- Global scale and resources
- Strong governance and compliance frameworks
- Extensive industry experience
Best for: Large-scale enterprise AI transformation
Limitations
- High cost
- Less flexibility compared to niche MLOps specialists
| Company | Best For | Strength | Limitation |
|---|---|---|---|
| Credencys | End-to-end MLOps transformation | Data + AI + MLOps expertise | More specialized and agile |
| Turing | Talent sourcing | Fast scaling | Limited strategy |
| Markovate | AI product development | Innovation-focused | Not enterprise-heavy |
| Intellias | Digital engineering | Scalable systems | MLOps is not the core focus |
| Accenture | Enterprise transformation | Global reach | Expensive |
How to Choose the Right MLOps Company
Selecting the right MLOps partner requires a structured approach. Beyond evaluating capabilities, you need to ensure alignment with your organization’s current maturity, future goals, and operational complexity.
Here’s a step-by-step framework to guide your decision:
1. Assess Your Current MLOps Maturity
Before evaluating vendors, you need clarity on where you stand. Ask:
- Are your data science teams still experimenting in silos?
- Do you have models in production but struggling with monitoring?
- Are you scaling AI across multiple business units?
Your answers will determine whether you need:
- Foundational MLOps setup
- Optimization and scaling
- Enterprise-wide governance and standardization
Choosing a partner aligned with your maturity prevents overengineering or under-delivery.
2. Validate End-to-End Ownership
Many organizations make the mistake of hiring separate vendors for:
- Data engineering
- Model development
- Deployment
This often leads to misalignment and delays. Instead, prioritize partners who can own the entire MLOps lifecycle. This ensures:
- Faster implementation
- Better accountability
- Seamless integration across stages
Ask for case studies that demonstrate full lifecycle delivery, not just isolated capabilities.
3. Evaluate Architecture and Tooling Approach
A good MLOps company doesn’t just implement tools; it designs future-proof architectures. During evaluation:
- Ask how they select tools and platforms
- Understand how they avoid vendor lock-in
- Evaluate their approach to integrating with existing systems
The goal is to ensure flexibility, scalability, and long-term sustainability.
4. Look for Industry Alignment and Use Cases
Generic AI expertise is not enough for enterprise success. Request:
- Industry-specific case studies
- Demonstrations of similar use cases
- References from companies in your domain
This helps you gauge how quickly the partner can deliver value in your specific context.
5. Assess Collaboration and Operating Model
MLOps is not a one-time project; it’s an ongoing capability. Your partner should:
- Work closely with your internal teams
- Provide knowledge transfer and training
- Offer flexible engagement models (project-based, managed services, etc.)
Strong collaboration ensures long-term success rather than short-term delivery.
6. Focus on ROI and Business Outcomes
Ultimately, MLOps should drive measurable business value. Evaluate partners based on their ability to:
- Reduce model deployment time
- Improve model accuracy and performance
- Lower operational costs
- Increase business impact (e.g., revenue, efficiency)
Avoid vendors who focus only on technical metrics without linking them to business outcomes.

Common MLOps Challenges Enterprises Face
Even with the right intent and investment, many organizations struggle to operationalize machine learning effectively. These challenges often stem from a lack of structured processes, fragmented tooling, and limited operational expertise.
Let’s explore the most common issues in detail:
1. Model Deployment Bottlenecks
One of the biggest gaps in AI adoption is the transition from experimentation to production. Data scientists often build models in isolated environments, but:
- Deployment requires coordination with engineering teams
- Infrastructure dependencies create delays
- Lack of standardized processes leads to inconsistencies
As a result, models remain stuck in development, delaying business impact.
2. Limited Visibility and Monitoring
Once models are deployed, many organizations lack proper monitoring mechanisms. This leads to:
- No visibility into model performance over time
- Inability to detect issues early
- Reactive rather than proactive maintenance
Without monitoring, even high-performing models can silently degrade, impacting business outcomes.
3. Data Drift and Model Drift
Real-world data is constantly changing. Over time:
- Input data distributions shift (data drift)
- Model accuracy declines (model drift)
Without automated detection and retraining pipelines, models become unreliable and produce inaccurate predictions.
4. Fragmented Tooling and Workflows
Many enterprises use multiple tools across the ML lifecycle: data processing, training, deployment, and monitoring. This creates:
- Integration challenges
- Data silos
- Increased operational complexity
A lack of unified architecture leads to inefficiencies and higher costs.
5. Lack of Standardization and Reusability
In many organizations, ML workflows are built from scratch for each use case. This results in:
- Duplication of effort
- Inconsistent practices across teams
- Difficulty scaling AI initiatives
Standardized pipelines and reusable components are essential for scaling efficiently.
6. Governance and Compliance Challenges
As AI adoption grows, so do regulatory requirements. Organizations often struggle with:
- Explaining how models make decisions
- Tracking changes to models and datasets
- Ensuring compliance with industry regulations
Without proper governance frameworks, AI initiatives can introduce significant risk.
7. Talent and Skill Gaps
MLOps requires a combination of skills:
- Data engineering
- Machine learning
- DevOps
Finding professionals with this hybrid expertise is challenging.
This often leads to:
- Overburdened teams
- Delayed implementations
- Suboptimal solutions
Final Thoughts
MLOps is no longer a “nice-to-have” capability; it has become the backbone of successful AI adoption in modern enterprises. While many organizations have made significant investments in data science and machine learning, the real challenge lies in turning those investments into consistent, scalable business outcomes.
Without a structured MLOps strategy, even the most advanced models remain underutilized, siloed, or quickly become obsolete in dynamic business environments. This is why MLOps is critical.
It transforms machine learning from isolated experimentation into a repeatable, production-grade system that continuously delivers value. However, achieving this transformation is not just about implementing tools or hiring a few specialists.
It requires:
- A well-defined architecture that integrates data, models, and infrastructure
- Standardized workflows that enable collaboration across teams
- Automation to reduce manual effort and accelerate deployment cycles
- Continuous monitoring to ensure models remain accurate and relevant over time
And most importantly, it requires a strategic partner who understands both the technical and business sides of AI. The right MLOps company doesn’t just help you deploy models; they help you:
- Build a scalable AI foundation aligned with long-term business goals
- Reduce time-to-market for new ML initiatives
- Improve model reliability and performance
- Minimize operational risks and costs
- Enable enterprise-wide adoption of AI
As AI continues to evolve, especially with the rise of real-time analytics and generative AI, the importance of MLOps will only grow. Organizations that invest in strong MLOps capabilities today will be better positioned to innovate faster, respond to market changes, and maintain a competitive edge.
On the other hand, those who delay may find themselves stuck in a cycle of experimentation without tangible returns. In this landscape, choosing the right MLOps partner becomes a critical decision.
If your goal is to move beyond pilot projects and build scalable, enterprise-grade AI systems, partnering with an experienced provider like Credencys can accelerate your journey. With the right expertise, tools, and strategy in place, you can transform your machine learning initiatives into measurable, long-term business success.



![Best Business Intelligence Companies in 2026 [Expert Picks]](https://www.credencys.com/wp-content/uploads/2026/03/Best-Business-Intelligence-Companies_thumb.jpg)