


How Databricks Architecture Powers Unified Data Analytics
Today, enterprises are collecting more data than ever before, but many still struggle to turn that data into actionable insights. This is largely due to fragmented tools and siloed teams handling data engineering, machine learning (ML), and business intelligence (BI) separately.
Did you know? Only 24% of organizations say they have a data strategy that successfully aligns business and IT teams. – Forrester
This disconnect leads to delays, inefficiencies, and missed opportunities. Enter Databricks; a unified data platform built on a modern architecture that breaks down these silos.
By integrating all data workloads under a single platform, Databricks architecture enables seamless collaboration between data engineers, scientists, and analysts, helping organizations unlock the full potential of their data.
In this blog post, we will explore how the architecture of Databricks powers unified data analytics by combining scalable infrastructure, open standards, and a collaborative environment.
The Need for Unified Data Analytics
As businesses grow, so does their data. But simply having data isn’t enough, it needs to be processed, analyzed, and acted upon.
Unfortunately, many organizations still rely on separate tools for data engineering, machine learning, and business intelligence, each with its own infrastructure, formats, and governance models. This fragmented approach creates major roadblocks:
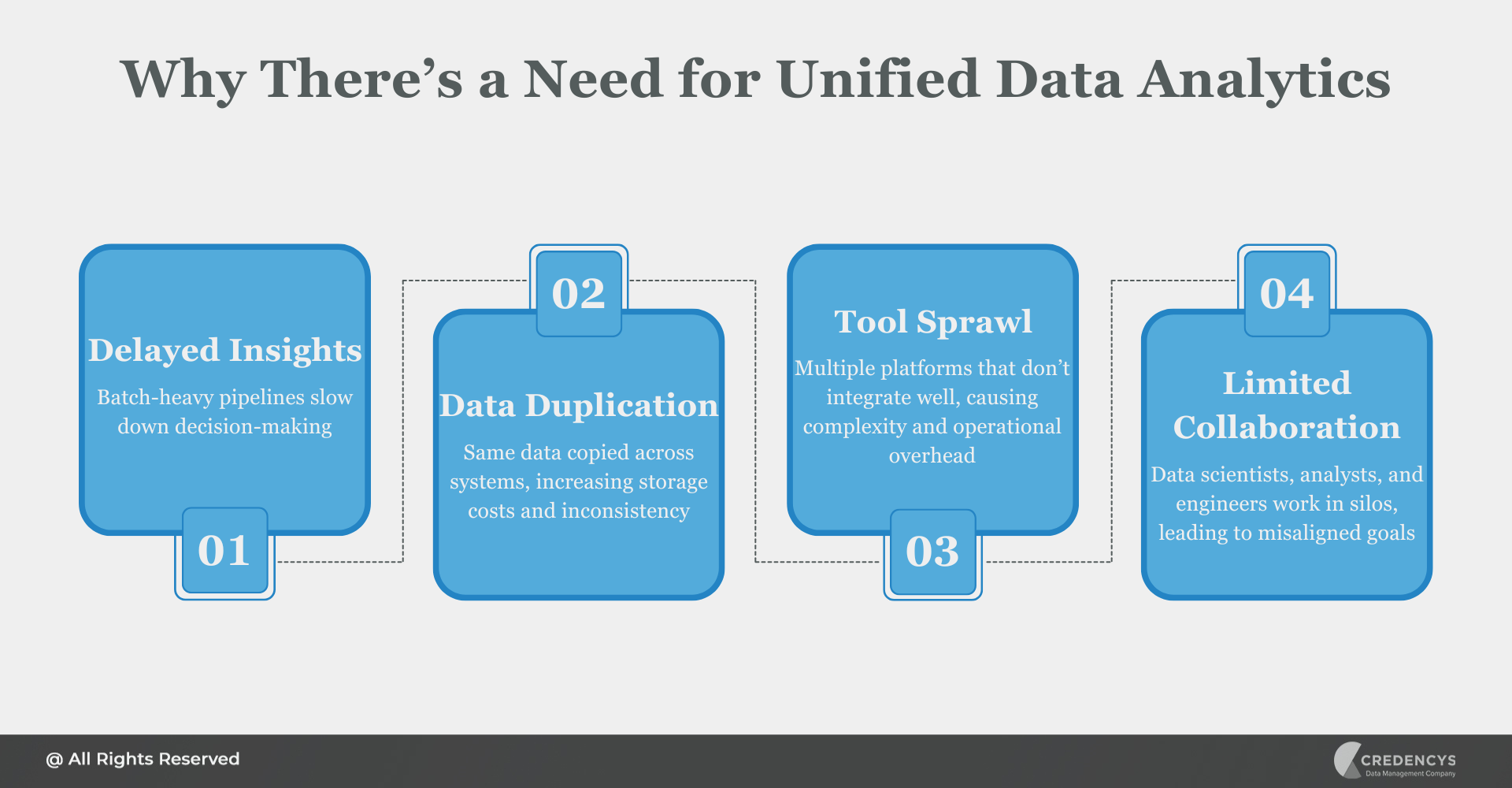
- Delayed insights: Batch-heavy pipelines slow down decision-making
- Data duplication: Same data copied across systems, increasing storage costs and inconsistency
- Tool sprawl: Multiple platforms that don’t integrate well, causing complexity and operational overhead
- Limited collaboration: Data scientists, analysts, and engineers work in silos, leading to misaligned goals
In today’s competitive environment, enterprises need a unified platform that supports the full analytics lifecycle, from raw data ingestion to real-time dashboards and predictive models, all in one place. That’s exactly what Databricks architecture enables.
Overview of Databricks Architecture
At the core of Databricks’ power is its Lakehouse architecture, a next-generation approach that blends the best features of data lakes and data warehouses. Built on open standards and cloud-native infrastructure, Databricks delivers a unified platform for all your data and AI workloads.
Let’s break down the key components of the Databricks architecture:
1. Delta Lake (Storage Layer)
- An open-source storage framework that brings ACID transactions to data lakes
- Enables scalable, reliable, and performant data pipelines
- Supports both batch and streaming data in a single format
2. Databricks Runtime
- An optimized engine built on Apache Spark
- Includes performance enhancements like Photon (vectorized query engine)
- Supports multiple languages: SQL, Python, Scala, R
3. Workspace & Notebooks
- A collaborative environment where engineers, analysts, and data scientists work together
- Supports version-controlled notebooks with built-in visualizations and interactive code execution
4. Unity Catalog
- Centralized governance layer for managing data access, lineage, and compliance
- Ensures secure, fine-grained access control across all data assets
5. Databricks SQL
- High-performance SQL engine for BI and dashboarding
- Native integrations with Power BI, Tableau, and other analytics tools
This modular but tightly integrated architecture allows teams to work with the same data without unnecessary data movement while maintaining security, performance, and flexibility.
Unlock the Full Potential of your Data with a Unified Architecture Built for Scale, Speed, and Collaboration
How Databricks Supports Business Intelligence and Analytics
Traditionally, business intelligence tools have relied on data warehouses, which often require moving data out of data lakes creating delays and inconsistencies. Databricks changes this by enabling high-performance analytics directly on data lake storage using its Lakehouse architecture.
Here’s how Databricks architecture supports modern BI:
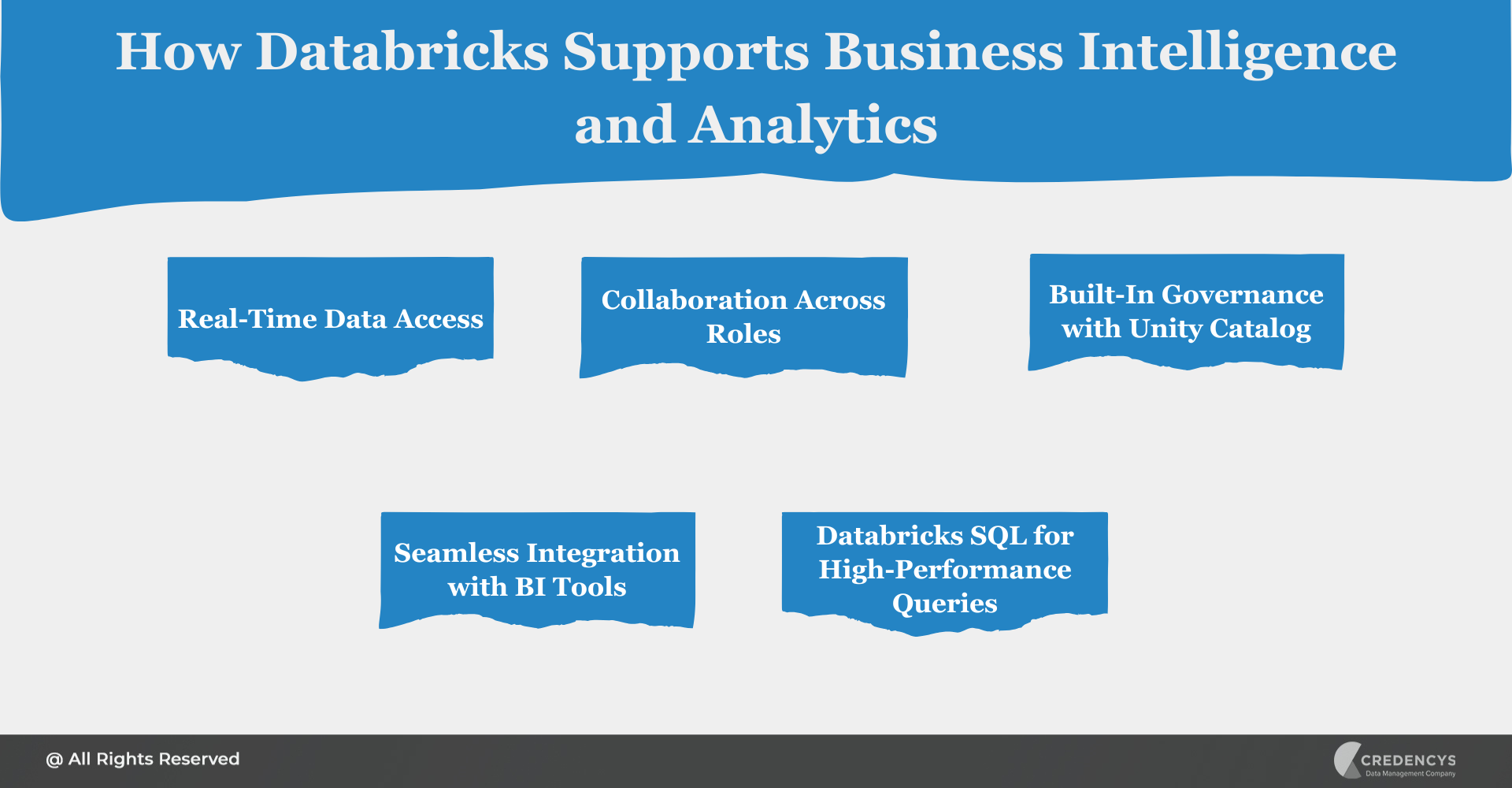
1. Real-Time Data Access
- Run analytics on streaming and batch data in near real-time
- Reduces latency between data ingestion and decision-making
2. Collaboration Across Roles
- Business users, analysts, and engineers can share notebooks, dashboards, and queries
- Promotes transparency and faster decision cycles
3. Built-In Governance with Unity Catalog
- Fine-grained access control ensures only the right users see the right data
- Enables secure collaboration across departments
4. Seamless Integration with BI Tools
- Native connectors for Power BI, Tableau, Looker, and others
- Analysts can query live Delta tables, no need for data extracts
5. Databricks SQL for High-Performance Queries
- A powerful SQL engine built for data analysts
- Offers fast query execution with the Photon engine
- Supports dashboarding and alerts directly within Databricks
By enabling real-time analytics without data duplication, Databricks gives decision-makers faster access to insights and helps organizations stay agile in a competitive landscape.
How Databricks Enables Unified Data Engineering
For data engineers, managing large-scale pipelines that handle both real-time and batch workloads can be complex, especially when juggling multiple tools. Databricks simplifies this by providing a unified environment to build, orchestrate, and scale data pipelines efficiently.
Here’s how Databricks architecture empowers modern data engineering:
1. Streamlined Ingestion with Auto Loader
- Automatically detects and ingests new files from cloud storage
- Handles schema inference and evolution, reducing manual work
2. Open File Formats for Flexibility
- Supports Delta, Parquet, JSON, and Avro formats
- Open standards mean no vendor lock-in and easier integration with other tools
3. Collaborative Notebooks
- Engineers, data scientists, and analysts can co-develop pipelines using Python, SQL, Scala, or R
- Real-time collaboration speeds up iteration and troubleshooting
4. Support for Batch and Streaming in One System
- Process streaming data in near real-time using the same tools used for batch processing
- Unified APIs simplify switching between modes based on business needs
5. Delta Live Tables for Declarative Pipelines
- Enables engineers to define data transformations as code or SQL logic
- Automatically handles orchestration, error handling, and recovery
- Ensures data quality with built-in expectations and monitoring
By combining automation, scalability, and openness, Databricks makes data engineering faster, more collaborative, and less error-prone.
How Databricks Powers Machine Learning and AI
Most organizations struggle to scale their machine learning efforts due to disjointed tools, inconsistent data access, and a lack of model governance. Databricks solves these challenges by offering a fully integrated ML environment that’s tightly coupled with its underlying architecture.
Here’s how the Databricks architecture accelerates the machine learning lifecycle:
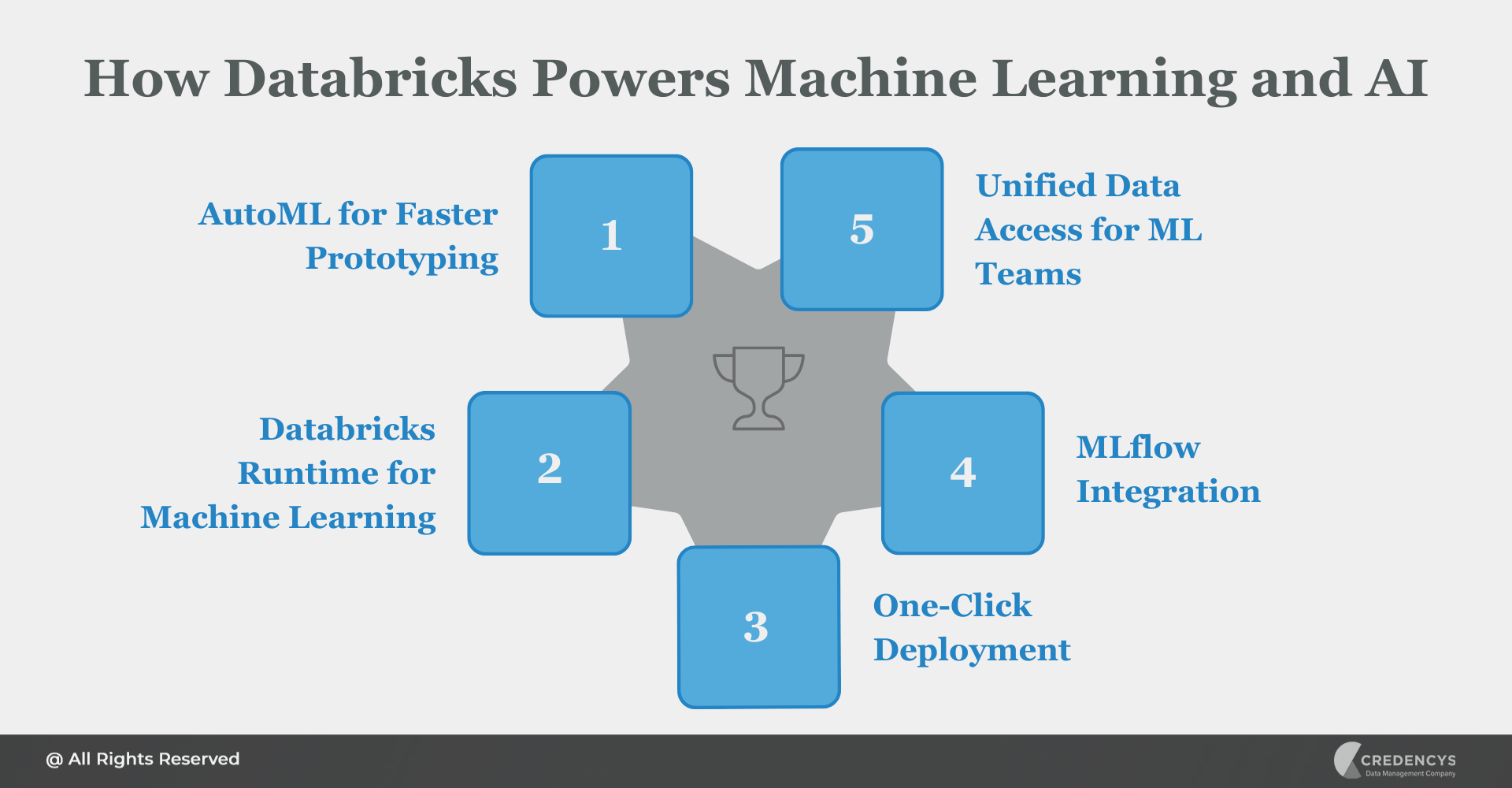
1. AutoML for Faster Prototyping
- Automates model selection, hyperparameter tuning, and feature engineering
- Helps data analysts and citizen data scientists build performant models quickly
2. Databricks Runtime for Machine Learning
- Pre-configured environments with popular libraries like TensorFlow, PyTorch, XGBoost, scikit-learn, and more
- Accelerated training using distributed computing across clusters
3. One-Click Deployment
- Models can be deployed as REST APIs directly from notebooks
- Supports batch and real-time inference through MLflow and Model Serving
4. MLflow Integration (Built-In)
- Experiment tracking, model versioning, and reproducibility out of the box
- Simplifies model management and deployment at scale
- Supports multiple frameworks and integrates with CI/CD tools
5. Unified Data Access for ML Teams
- ML models access the same clean, governed Delta tables used by analytics and BI teams
- No need to move or duplicate data between platforms
With Databricks, organizations can go from raw data to deployed ML models without jumping between systems saving time, reducing errors, and increasing productivity.
Accelerate your Machine Learning Journey with a Unified Platform That Takes You from Data to Deployment Seamlessly and at Scale
The Business Value of Databricks’ Unified Architecture
Databricks’ unified architecture isn’t just a technical advantage; it’s a strategic one. By consolidating data engineering, ML, and BI into a single platform, organizations unlock significant operational efficiencies, cost savings, and innovation opportunities.
1. Lower Total Cost of Ownership
- Eliminate the need for multiple tools and redundant infrastructure
- Reduce storage, maintenance, and integration overheads
2. Improved Collaboration
- Shared workspace enables engineers, scientists, and analysts to work together seamlessly
- Encourages cross-functional insights and innovation
3. Robust Governance and Security
- Unity Catalog ensures data access, lineage, and compliance are centrally managed
- Helps meet regulatory requirements and internal data policies
4. Scalable Across Teams and Use Cases
- Supports diverse workloads: from ad hoc queries to large-scale ML training
- Easily scales with growing data volumes and business needs
5. Faster Time-to-Insight
- Real-time access to consistent data reduces the time between data generation and decision-making
- Teams can collaborate without waiting on cross-department handoffs
Databricks architecture helps enterprises move from data chaos to data clarity, faster, smarter, and at scale.
Why Enterprises Choose Databricks for Unified Analytics
Enterprises across industries, from retail and manufacturing to eCommerce and financial services, are adopting Databricks because it offers a future-ready platform that scales with evolving data needs. Here’s why organizations trust Databricks for unified analytics:
1. Cloud-Native and Multi-Cloud Ready
- Deployable on AWS, Azure, and Google Cloud
- Optimized to scale elastically with cloud-native services and compute
2. AI and ML-Ready Architecture
- Native support for advanced analytics and machine learning workflows
- Makes AI accessible across departments, not just data science teams
3. Backed by Expert Partners Like Credencys
- Accelerate your Databricks implementation with certified consulting partners
- Get expert support on architecture design, migration, pipeline development, and governance
4. End-to-End Platform for All Roles
- One platform serves data engineers, data scientists, and business analysts alike
- Reduces the complexity of managing siloed teams and tools
5. Trusted by Leading Brands
- Used by companies like Shell, Comcast, HSBC, CVS Health, and Grab
- Real-world use cases prove its performance, reliability, and business impact
6. Built on Open-Source Standards
- Founded by the creators of Apache Spark, Delta Lake, and MLflow
- Avoids vendor lock-in with open, extensible architectures
- Encourages community innovation and interoperability

Whether you are modernizing legacy systems or scaling AI across your enterprise, Databricks provides the architecture and flexibility to make it happen quickly and securely.
Conclusion
Data is now the new competitive edge, and enterprises can no longer afford fragmented tools and disconnected teams. To stay ahead, they need a platform that enables real-time insights, cross-functional collaboration, and scalable innovation.
Databricks architecture delivers exactly that. By unifying data engineering, machine learning, and business intelligence on a single, open platform, Databricks empowers organizations to extract more value from their data faster and more efficiently than ever before.
Whether you are just starting your data modernization journey or looking to scale your AI capabilities, Databricks provides the foundation you need for long-term success.
Ready to Break Down Data Silos and Unlock Unified Analytics for your Business? Our Experts at Credencys can Accelerate your Journey with Tailored Architecture, Implementation, and Support





Tags: