


Data Quality for AI: How Poor Data Impacts Model Accuracy
Artificial intelligence is only as powerful as the data behind it. Enterprises are investing in AI to improve customer experiences, forecast demand, optimize pricing, automate operations, and make faster decisions.
But many AI initiatives fail to deliver reliable outcomes because the underlying data is not ready. AI models do not just need large volumes of data.
They need accurate, complete, consistent, timely, relevant, and well-governed data. When data is poor, AI models learn the wrong patterns.
They produce inaccurate predictions, biased recommendations, and unreliable outputs. This leads to low confidence among business users and delays broader adoption of AI.
For enterprises in retail, CPG, manufacturing, supply chain, and digital commerce, building an AI-ready data foundation is critical to improving model accuracy, business trust, and AI ROI. In this blog, we explore what data quality means for AI, how poor data impacts model accuracy, which data quality issues enterprises must address, and how organizations can build AI-ready data foundations.
What is Data Quality for AI?
Data quality for AI refers to how accurate, complete, consistent, timely, relevant, representative, and reliable data is for training, validating, deploying, and monitoring AI models. In traditional analytics, data quality is often measured by whether the data is correct and usable for reporting.
AI raises the bar. For AI and machine learning, data quality also includes factors such as:
- Whether the data represents real-world scenarios accurately
- Whether all required fields and records are complete
- Whether the data is consistent across systems
- Whether the data is current enough for the use case
- Whether the dataset is balanced and representative
- Whether labels or annotations are accurate
- Whether bias, noise, and duplicate records are controlled
- Whether data lineage and governance are maintained
A dashboard may tolerate minor inconsistencies in some cases. AI models often cannot.
When an AI model is trained on incomplete, biased, outdated, or incorrect data, those weaknesses can directly influence predictions. As a result, the model may perform well in controlled testing but fail in production when exposed to real-world conditions.
This is why enterprises need strong enterprise data quality management practices before scaling AI across business functions.
How Poor Data Quality Impacts AI Model Accuracy
AI models learn from the data they are given. If the training data contains errors, gaps, or bias, the model learns from those issues.
It may identify incorrect patterns, over-prioritize the wrong variables, or fail to generalize across different customer segments, product categories, or operating conditions. Even the most advanced AI/ML solutions cannot deliver reliable outcomes if they are trained on inaccurate, incomplete, or biased data.
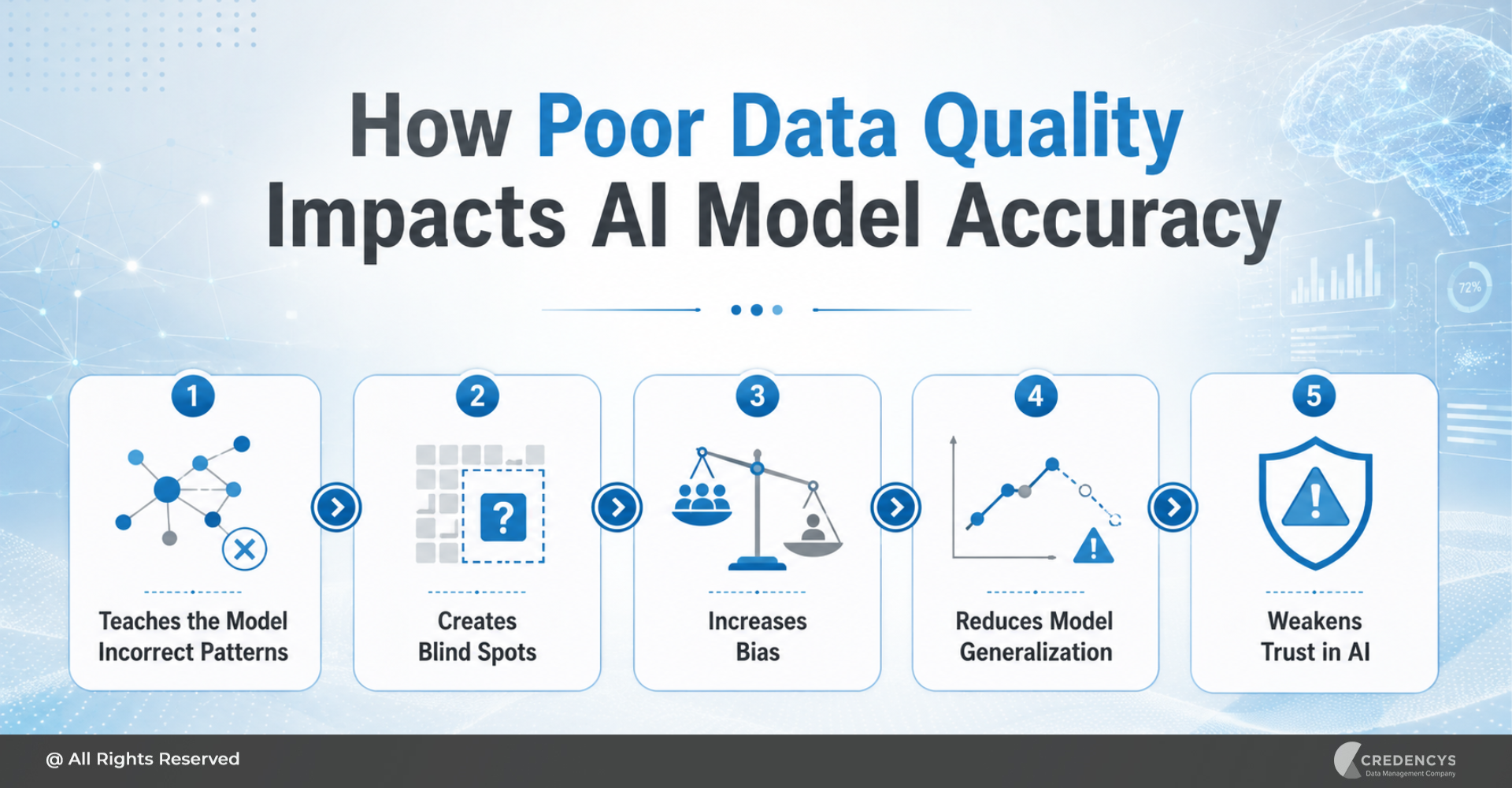
Poor data quality can impact AI model accuracy in several ways.
1. It Teaches the Model Incorrect Patterns
AI models identify relationships and patterns within data. If customer profiles, product attributes, transaction records, or inventory data are inaccurate, the model may learn patterns that do not reflect reality.
For example, if a retail recommendation model is trained on incorrect product categories, it may recommend irrelevant products to customers.
2. It Creates Blind Spots
Incomplete data limits what a model can learn. If important fields such as customer preferences, product availability, location, purchase frequency, or promotional history are missing, the model does not get the full context.
This weakens predictions and reduces confidence in AI outputs.
3. It Increases Bias
If a dataset overrepresents certain customer groups, regions, sales channels, or product categories, the model may perform better on those segments and worse on others. This can lead to unfair, inaccurate, or inconsistent outcomes.
4. It Reduces Model Generalization
A model should perform reliably on new data, not just historical data. Poor data quality can cause models to perform well during training but fail when applied to real-world scenarios.
This is especially risky for use cases like fraud detection, demand forecasting, and dynamic pricing.
5. It Weakens Trust in AI
Business users will not rely on AI outputs if the predictions are inconsistent or difficult to explain. Even a few incorrect recommendations or poor predictions can reduce stakeholder confidence and slow down adoption.
Common Data Quality Issues That Hurt AI Performance
To improve AI accuracy, enterprises must first understand the data quality issues that commonly affect model performance.
1. Inaccurate Data
Inaccurate data includes wrong values, incorrect product attributes, outdated customer information, faulty transaction records, or mismatched business entities. For example, if a customer’s location, purchase history, or preferences are incorrect, an AI personalization model may generate irrelevant recommendations.
Inaccurate data leads to inaccurate model outputs.
2. Incomplete Data
Incomplete data occurs when important fields, records, or attributes are missing. Examples include:
- Customer profiles without demographic or behavioral data
- Product records without complete specifications
- Sales records without channel or location details
- Inventory data without real-time stock availability
- Supplier data without delivery or risk indicators
Incomplete data prevents AI models from understanding the full business context.
3. Inconsistent Data
Inconsistent data appears when different systems define, format, or store the same information differently. For example:
- One system records “USA,” while another records “United States”
- Product sizes are stored in different units
- Customer names are formatted differently across CRM and eCommerce platforms
- Product categories vary between PIM, ERP, and marketplace systems
These inconsistencies create confusion across data pipelines and weaken the reliability of AI models. This is where Master Data Management helps enterprises create trusted records for customers, products, suppliers, and locations.
4. Duplicate Records
Duplicate customer, product, supplier, or location records can distort AI training. A customer may appear multiple times under slightly different names.
A product may have duplicate SKUs across systems. A supplier may be listed differently in procurement and ERP platforms.
Duplicates can make models overcount patterns, misread behavior, or generate conflicting outputs.
5. Outdated Data
AI models need timely data to stay relevant. Models trained on outdated customer behavior, old pricing trends, stale inventory data, or past market conditions may fail to reflect the current business environment.
This is a major concern in retail, CPG, and supply chain operations where demand, pricing, and customer behavior change quickly.
6. Biased or Unrepresentative Data
If the dataset does not represent the full population or range of scenarios the model will encounter, predictions may become biased or unreliable. For example, a demand forecasting model trained primarily on high-performing regions may not perform well in emerging markets or seasonal product categories.
7. Incorrect Labels or Annotations
For supervised learning models, labels act as the “truth” the model learns from. If labels are incorrect, incomplete, inconsistent, or subjective, the model learns the wrong associations.
This is common in image recognition, customer classification, fraud detection, and support ticket categorization. Poor labels directly reduce model accuracy.
How Poor Data Quality Affects Business Outcomes
Poor data quality not only affects model performance. It affects business outcomes.
When AI models are built on unreliable data, enterprises may experience inaccurate forecasts, poor customer experiences, inefficient operations, and lower trust in AI-driven decisions.
1. Inaccurate Forecasting
Demand forecasting models depend on clean historical sales, inventory, promotions, seasonality, and external signals. If this data is incomplete or outdated, forecasts may miss shifts in demand.
This can lead to stockouts, overstocking, lost revenue, and increased carrying costs.
2. Poor Personalization
Personalization depends on a clear understanding of the customer. If customer profiles are fragmented, duplicated, or outdated, AI systems may recommend irrelevant products, send poorly timed offers, or deliver inconsistent experiences across channels.
3. Wrong Pricing Decisions
Dynamic pricing models depend on accurate product, inventory, demand, competitor, and margin data. Poor data can lead to pricing decisions that hurt profitability, reduce competitiveness, or create customer dissatisfaction.
4. Lower Operational Efficiency
AI models used for supply chain, procurement, logistics, or production planning need reliable operational data. If supplier data, inventory records, shipment information, or material data are inconsistent, AI-driven recommendations may not support the right actions.
5. Reduced Trust in AI
When business users see incorrect predictions or unreliable recommendations, they begin to question the value of AI.
This slows adoption and makes it harder for organizations to scale AI initiatives across departments.

Data Quality Metrics Every AI Program Should Track
AI programs need measurable data quality standards. Without clear metrics, teams cannot identify problems, prioritize improvements, or monitor whether data is truly ready for AI.
Here are the key data quality metrics enterprises should track.
| Metric | What It Measures | Why It Matters for AI |
|---|---|---|
| Accuracy | Whether data reflects real-world entities or events | Prevents incorrect predictions |
| Completeness | Whether required fields and records are present | Reduces blind spots in model training |
| Consistency | Whether data is aligned across systems | Prevents conflicting signals |
| Validity | Whether data follows required formats and rules | Improves usability for pipelines and models |
| Uniqueness | Whether duplicate records are removed | Prevents skewed learning |
| Timeliness | Whether data is current and available when needed | Keeps predictions relevant |
| Integrity | Whether relationships between records remain valid | Improves trust across datasets |
| Coverage | Whether all relevant scenarios and segments are represented | Improves model generalization |
| Bias | Whether data is balanced and fair | Reduces unfair or inaccurate outcomes |
| Label Quality | Whether labels or annotations are correct | Improves supervised model accuracy |
These metrics should not be tracked once and forgotten. AI-ready data quality requires continuous monitoring across ingestion, transformation, training, deployment, and production environments.
How to Improve Data Quality for AI Models
Improving data quality for AI requires a structured approach. Enterprises need to combine data engineering, governance, observability, and continuous feedback from AI systems.
1. Start with Data Profiling
Data profiling helps teams understand the current state of enterprise data. It identifies missing values, duplicates, outliers, format issues, inconsistent fields, and unusual patterns.
This gives data and AI teams visibility into whether the data is fit for model training and production use. Before building AI models, organizations should profile data from CRM, ERP, POS, eCommerce, PIM, MDM, supply chain, and marketing systems.
2. Build Data Quality Rules into Pipelines
Data quality should not be handled manually at the end of the process. Validation rules should be embedded directly into data pipelines.
These may include:
- Null checks
- Range checks
- Format validation
- Schema validation
- Duplicate detection
- Standardization rules
- Referential integrity checks
This helps ensure that poor-quality data is detected before it reaches AI models.
3. Clean and Standardize Data
Data cleansing improves the accuracy and usability of data. This may involve correcting errors, removing duplicates, standardizing formats, fixing inconsistent values, enriching incomplete records, and aligning business definitions across systems.
For AI use cases, standardization is especially important because models need consistent inputs to generate reliable outputs.
4. Improve Master Data Management
Master Data Management helps enterprises create trusted records for critical business entities such as customers, products, suppliers, locations, and materials. For AI models, this is extremely valuable.
A unified customer record improves personalization. A clean product record improves recommendations and pricing. A trusted supplier record improves procurement and supply chain intelligence.
MDM reduces duplication, improves consistency, and creates a stronger foundation for AI-driven decisions.
5. Strengthen Data Governance
Data governance defines how data is owned, managed, accessed, and protected. For AI, governance should include:
- Data ownership
- Stewardship workflows
- Access controls
- Data lineage
- Quality thresholds
- Compliance policies
- Usage guidelines
- Model input accountability
Governance ensures that AI systems are not only accurate but also responsible and trustworthy.
6. Implement Data Observability
Data observability helps teams continuously monitor data health. It tracks freshness, schema changes, volume changes, data drift, pipeline failures, and quality issues.
This is important because data quality can degrade over time as systems, processes, and business conditions change. With observability, teams can detect issues earlier and reduce the risk of poor data affecting AI models in production.
7. Create Feedback Loops Between Models and Data Teams
AI model performance can reveal hidden data problems. For example, if a model performs poorly for a specific customer segment, product category, or region, the root cause may be missing data, biased data, outdated records, or incorrect labels.
Feedback loops between data engineers, data scientists, and business teams help identify these issues and continuously improve the data foundation.

The Role of AI in Data Quality Management
AI is affected by data quality, but it can also help improve data quality. Modern AI-powered data quality tools can help enterprises detect issues faster, automate repetitive checks, and prioritize problems with the greatest business impact.
AI can support data quality management by:
- Detecting anomalies in large datasets
- Identifying duplicate records
- Suggesting data quality rules
- Finding missing or unusual values
- Detecting schema changes and data drift
- Classifying unstructured data
- Prioritizing issues based on downstream impact
- Recommending remediation actions
This becomes especially valuable as data volumes grow and enterprise environments become more complex. Instead of relying only on manual checks, organizations can use AI-assisted data quality management to continuously monitor and improve data across pipelines, platforms, and business domains.
For enterprises scaling AI initiatives, this creates a powerful cycle: better data improves AI performance, and AI helps improve data quality.
Data Quality for AI in Retail and CPG
Retail and CPG businesses depend on accurate, connected, and timely data for AI to work. From personalization to forecasting, product recommendations, pricing, and supply chain planning, every AI use case depends on the quality of customer, product, inventory, and transaction data.
1. Customer 360 and Personalization
Customer 360 solutions require accurate and deduplicated customer data from CRM, POS, eCommerce, loyalty, mobile, and marketing platforms. If customer data is fragmented, AI models may not understand the complete customer journey.
This affects recommendations, offers, segmentation, and engagement. Clean and unified customer data strengthens Customer 360 solutions and enables more accurate personalization.
2. Demand Forecasting
Demand forecasting models require clean historical data on sales, inventory, promotions, pricing, seasonality, and external signals. Missing or outdated data can reduce forecast accuracy and affect replenishment planning.
Accurate sales, inventory, and market data can improve AI demand forecasting for retail and CPG businesses.
3. Dynamic Pricing
Pricing AI depends on accurate data on products, inventory, competitors, demand, costs, and margins. If data quality is poor, pricing models may recommend prices that hurt revenue, margins, or customer trust.
Clean product, margin, inventory, and demand data are essential for effective AI dynamic pricing.
4. Product Recommendations
Recommendation engines depend on accurate product attributes, customer behavior, availability, purchase history, and browsing patterns. Poor product data can lead to irrelevant suggestions and lower conversion rates.
5. Supplier and Inventory Intelligence
AI-driven supply chain decisions require trusted data on suppliers, materials, logistics, and inventory. When supplier or inventory data is inconsistent, AI models may fail to identify risks, forecast shortages, or recommend appropriate operational actions.

How Credencys Helps Enterprises Build AI-Ready Data Quality
Improving AI accuracy requires more than model tuning. It requires a trusted data foundation.
Credencys helps enterprises assess, clean, govern, and modernize their data ecosystems so AI systems can operate on accurate, complete, and business-ready information. With expertise across data engineering services, data integration, Master Data Management, Product Information Management, Customer 360, Databricks, Snowflake, AI/ML solutions, and data governance, Credencys helps organizations build reliable data foundations for enterprise AI.
Our teams help businesses:
- Identify data quality gaps
- Modernize data pipelines
- Unify customer, product, and supplier data
- Improve data governance and observability
- Build AI-ready lakehouse architectures
- Enable reliable analytics and AI/ML workflows
- Support retail, CPG, manufacturing, and supply chain use cases
For enterprises that want to scale AI, improving data quality is one of the most important steps toward better accuracy, stronger trust, and measurable business outcomes.
Conclusion
AI success starts with data quality. Poor data leads to unreliable predictions, biased outputs, low user trust, and wasted AI investment.
High-quality data, on the other hand, helps AI models become more accurate, reliable, and useful for business decision-making. As enterprises expand AI across customer experience, pricing, forecasting, operations, and supply chain intelligence, data quality must become a strategic priority.
Before scaling AI, organizations need to ensure their data is accurate, complete, consistent, timely, governed, and ready for model training and production use. Better data creates better AI. Better AI creates better business decisions.
FAQs
1. What is data quality for AI?
Data quality for AI refers to how accurate, complete, consistent, timely, relevant, representative, and reliable data is for training, validating, deploying, and monitoring AI models.
2. How does poor data quality affect AI model accuracy?
Poor data quality can lead to inaccurate predictions, biased outcomes, overfitting, poor generalization, and reduced confidence in AI-driven decisions.
3. What are the most common data quality issues in AI?
Common issues include missing values, duplicate records, inconsistent formats, outdated data, biased datasets, incorrect labels, outliers, and incomplete coverage.
4. Which data quality metrics matter most for AI?
Important data quality metrics for AI include accuracy, completeness, consistency, validity, uniqueness, timeliness, integrity, coverage, bias, and label quality.
5. How can enterprises improve data quality for AI?
Enterprises can improve data quality through profiling, cleansing, validation, Master Data Management, governance, observability, automated quality checks, and continuous monitoring.





Tags: