


Databricks RAG Architecture vs Traditional LLM Architectures: What’s the Difference?
The rise of generative AI has unlocked transformative capabilities for businesses, from AI-powered chatbots to intelligent search assistants and personalized content generation. At the heart of these innovations lie large language models (LLMs), capable of understanding and generating human-like responses.
However, as enterprises strive to apply LLMs to their unique data and domains, a critical limitation emerges. Traditional LLM architectures often lack real-time, context-aware, and trustworthy responses based on proprietary knowledge.
According to a 2024 Forrester report, over 68% of enterprises deploying LLMs cite hallucination and lack of domain grounding as key barriers to production readiness.
This is where Retrieval-Augmented Generation (RAG) comes in: a new architectural pattern that enhances LLMs by connecting them to external data sources. RAG allows AI systems to “retrieve” relevant information from databases or document stores before generating a response, significantly improving accuracy and domain relevance.
Among the platforms leading this evolution is Databricks, which empowers organizations to implement scalable and secure RAG pipelines using its unified Lakehouse architecture, MLflow, Delta Lake, and Unity Catalog. In this blog, we’ll compare traditional LLM architectures with RAG-powered ones and explore how Databricks RAG Architecture uniquely bridges structured and unstructured data to deliver more accurate, enterprise-grade AI outcomes.
What is a Traditional LLM Architecture?
A traditional LLM architecture relies solely on a pre-trained large language model that generates responses based on the knowledge it has absorbed during training. These models, such as OpenAI’s GPT, Meta’s LLaMA, or Google’s Gemini, are trained on massive datasets containing books, websites, code, and more.
Once trained, they operate in a “closed box” manner. All responses are generated from internal knowledge, without referencing any external or up-to-date information.
How It Works
- The user inputs a query or prompt.
- The LLM uses its internal parameters (often hundreds of billions) to generate a response.
- The output is based purely on correlations learned during training and not on any live or domain-specific data.
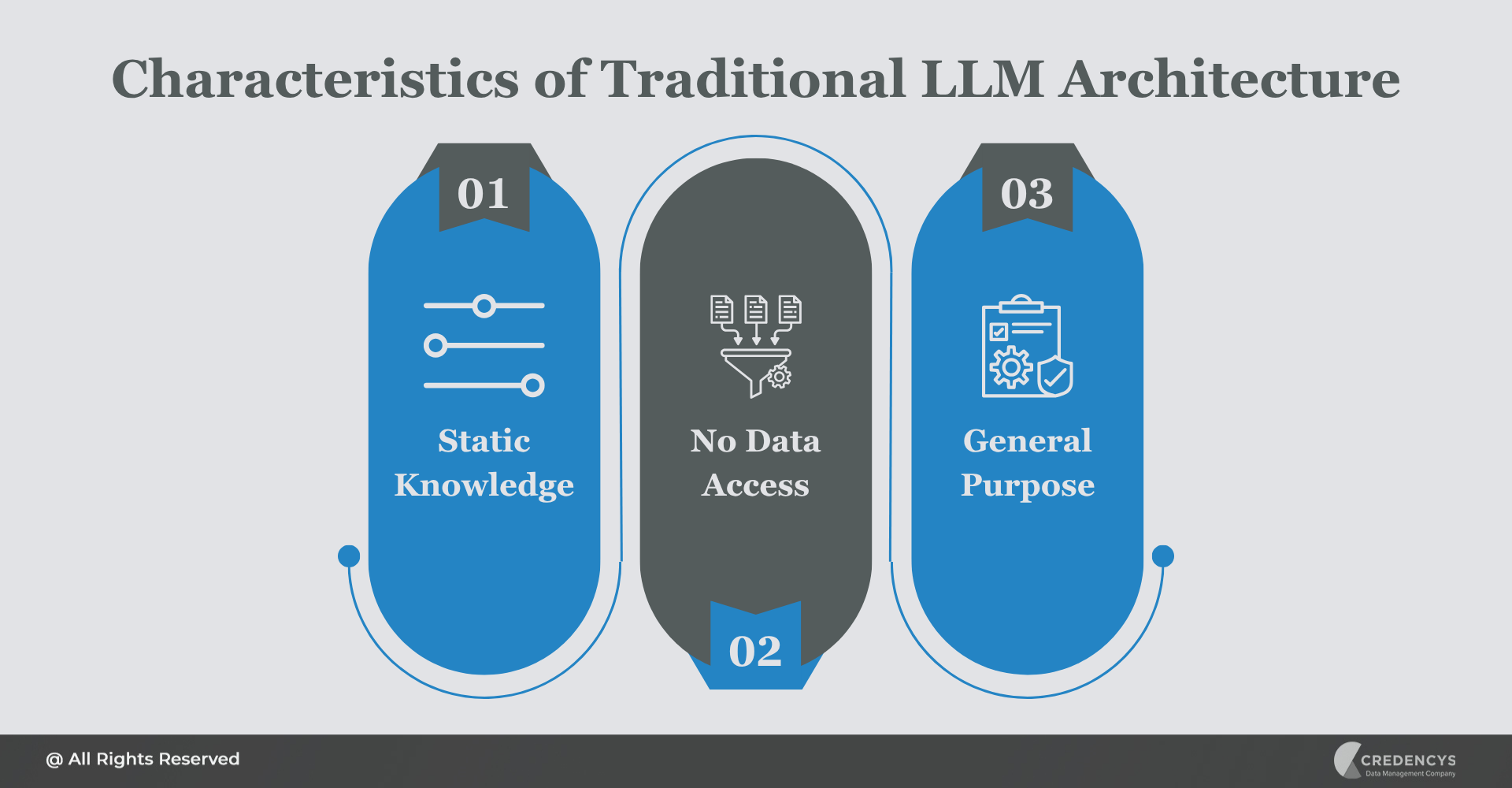
Key Characteristics
- Static Knowledge: The model’s knowledge is frozen at the point of its last training cycle.
- No Data Access: Cannot retrieve real-time data from databases, APIs, or document repositories.
- General Purpose: Designed for broad, non-specific applications.
Limitations
- Poor Fit for Enterprises: Without the ability to pull in real-time or proprietary data, they fall short in business-critical applications like customer support, compliance, or domain-specific Q&A.
- Lack of Contextual Relevance: They can’t tailor answers based on a company’s internal documents, customer records, or product data.
- Hallucinations: Traditional LLMs often generate plausible but incorrect or fabricated information.
In enterprise environments, where accuracy, trust, and data control are non-negotiable, these limitations pose a major roadblock.
What is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is a game-changing architecture that enhances the capabilities of traditional large language models by allowing them to access and use external data at inference time. Instead of relying solely on what the model has memorized during training, RAG architectures dynamically retrieve relevant information from external knowledge sources like documents, databases, or enterprise systems before generating a response.
This hybrid approach significantly boosts the accuracy, contextual relevance, and trustworthiness of AI-generated outputs.
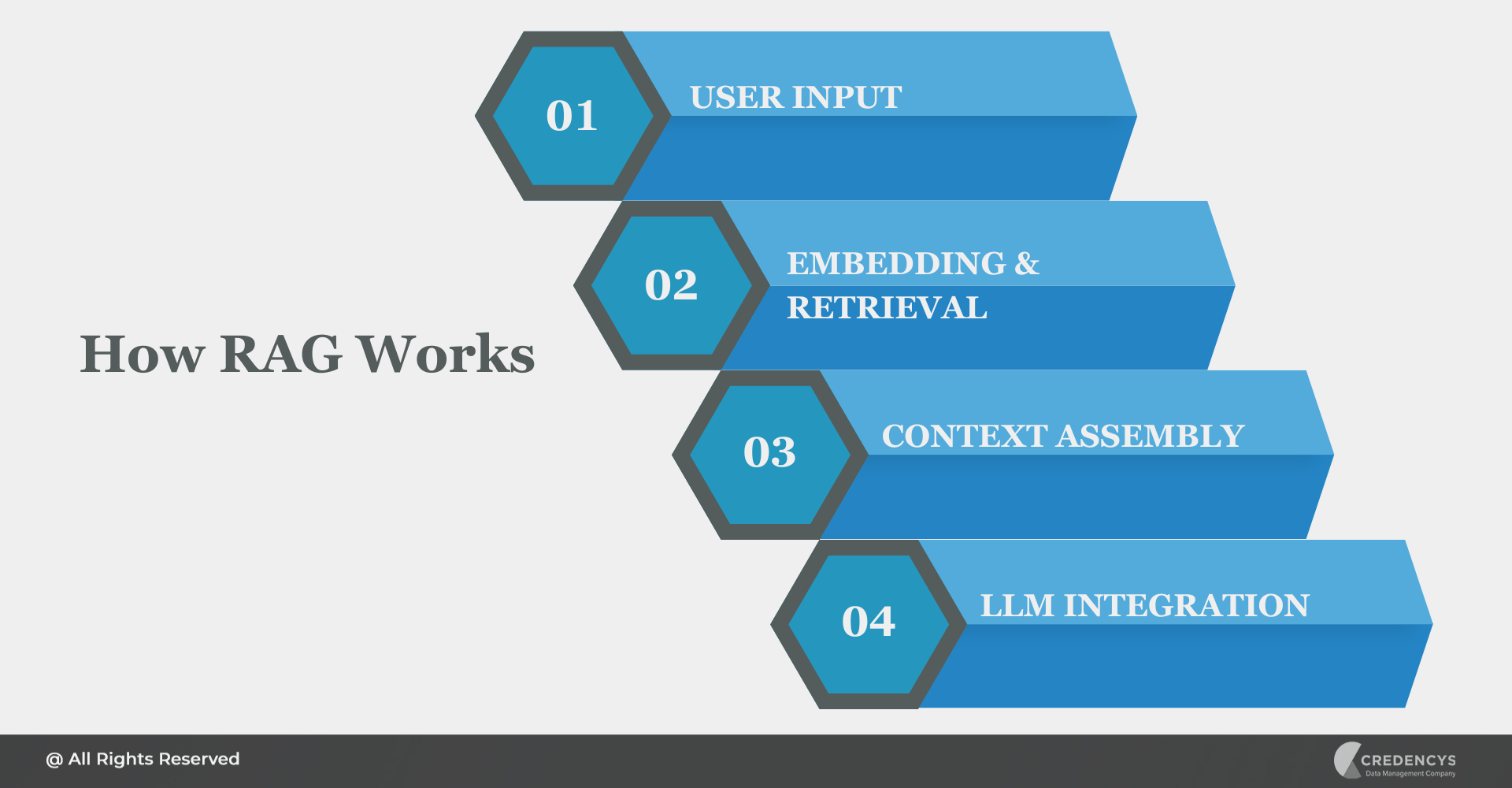
How RAG Works
- User Input: A user submits a question or prompt.
- Embedding & Retrieval:
- The input is converted into a vector using an embedding model.
- This vector is used to search a vector database (e.g., containing documents, knowledge base articles, etc.).
- Context Assembly:
- Top-k relevant results are retrieved based on semantic similarity.
- These results are combined to form a contextual input.
- LLM Generation:
- The retrieved context is passed along with the original query to the LLM.
- The model generates a response grounded in both its training and the newly retrieved data.
Want to See how RAG can Transform your Enterprise Data into Intelligent, Context-Aware Answers?
Benefits of RAG
- Smaller, More Efficient Models: Enables the use of smaller LLMs without sacrificing relevance.
- Enterprise Adaptability: Tailors responses to specific business domains, workflows, or datasets.
- Fresh, Real-Time Knowledge: Pulls in the most recent documents or records.
- Improved Accuracy: Reduces hallucinations by grounding responses in real data.
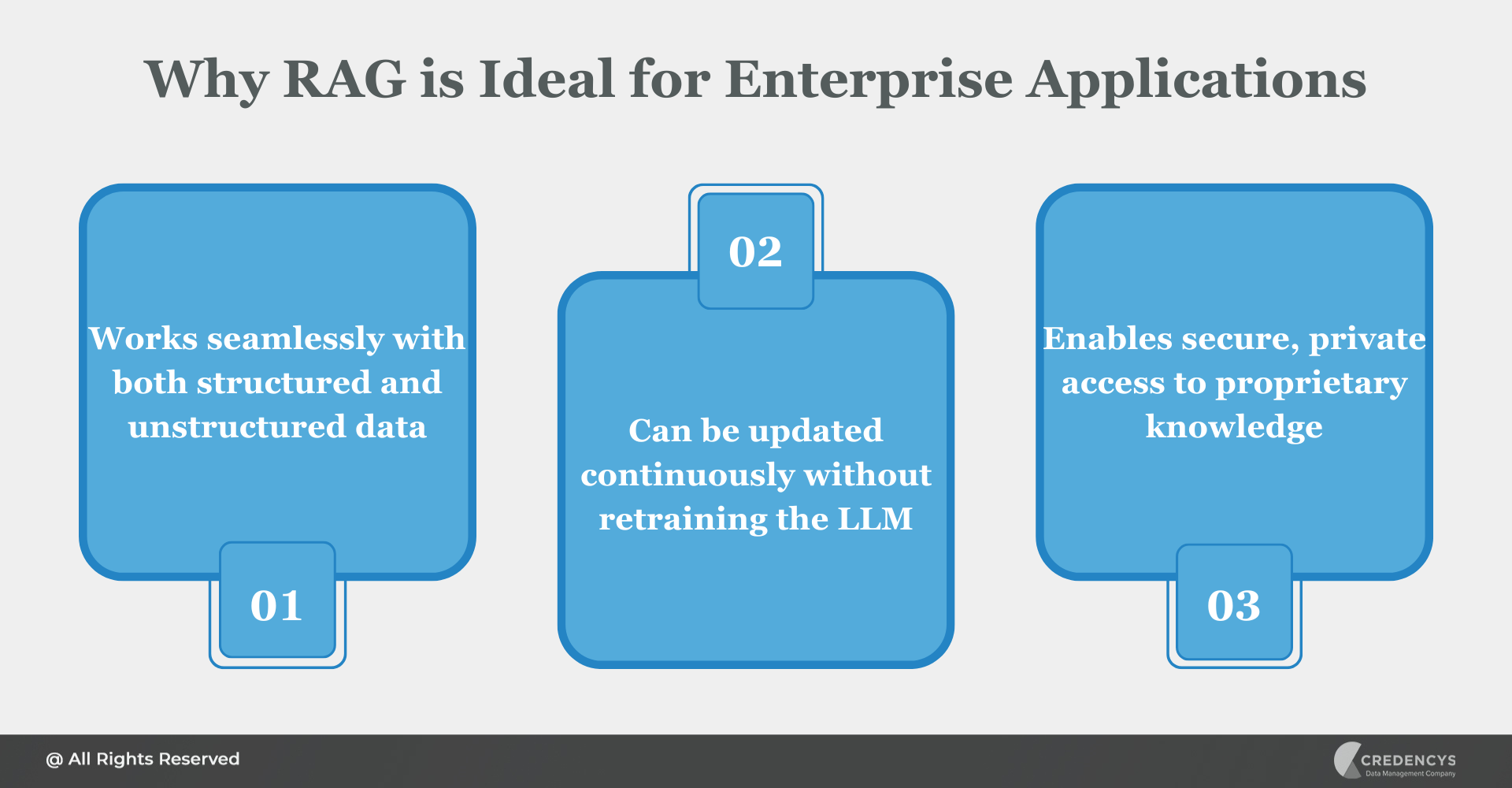
Why RAG is Ideal for Enterprise Applications
- Works seamlessly with both structured and unstructured data.
- Can be updated continuously without retraining the LLM.
- Enables secure, private access to proprietary knowledge.
In essence, RAG transforms LLMs from isolated knowledge containers into dynamic, enterprise-aware AI assistants.
Databricks RAG Architecture vs Traditional LLM Architectures: Key Differences
Now that we’ve explored the foundations of both traditional LLMs and RAG, let’s compare the two approaches across key dimensions. This side-by-side comparison highlights why Databricks RAG Architecture is better suited for real-world, enterprise-grade AI applications.
| Key Aspects | Traditional LLM Architecture | Databricks RAG Architecture |
|---|---|---|
| Data Access | Limited to static training data | Dynamic retrieval from enterprise sources (Delta Lake, documents, APIs) |
| Response Accuracy | High risk of hallucinations | Grounded in real-time, factual data |
| Domain Relevance | Generic, pre-trained knowledge | Custom embeddings trained on proprietary data |
| Scalability | May require fine-tuning large models | Modular, scalable with Databricks clusters and vector search |
| Update Flexibility | Requires model retraining | Just update the data source, no retraining needed |
| Structured + Unstructured Data Support | Poor integration | Native support via Delta Lake and Unity Catalog |
| Governance & Security | Limited control | Fine-grained governance with Unity Catalog |
| Operationalization | Often fragmented toolchains | End-to-end pipeline: MLflow, Delta, vector search, orchestration; all on Databricks |
Key Takeaways
- Traditional LLMs are best for general-purpose use cases where accuracy is less critical.
- RAG with Databricks is ideal for enterprise applications that demand precision, context, scalability, and governance.
If you’re building an AI solution that needs to answer based on your company’s latest documents, product catalogs, or policies, Databricks RAG is the architecture you need.
When Should You Choose RAG with Databricks?
While traditional LLMs can be powerful out of the box, they fall short in many enterprise contexts where accuracy, personalization, and data control are mission-critical. If your organization is looking to deploy reliable, domain-specific AI applications, RAG with Databricks offers a future-ready foundation.
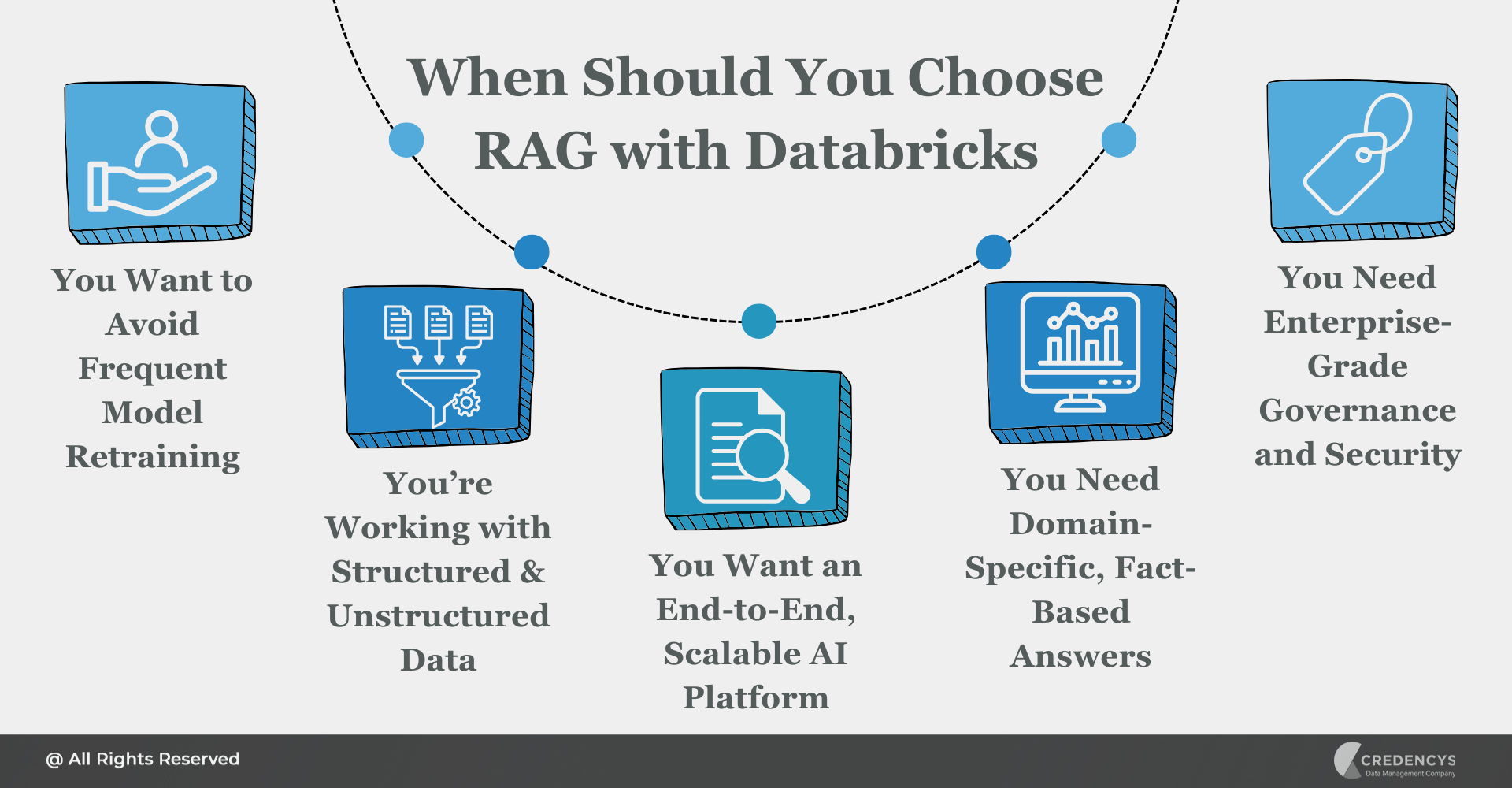
Here are the key scenarios where Databricks RAG Architecture is the right choice:
1. You Want to Avoid Frequent Model Retraining
With RAG, updating the underlying data store is enough; there’s no need to retrain your LLM every time a document changes. Databricks enables seamless retrieval and context injection using the latest available content.
2. You’re Working with a Mix of Structured and Unstructured Data
Most businesses deal with tables, PDFs, emails, and more. Databricks makes it easy to unify this diverse data within Delta Lake and make it retrievable in real time.
3. You Want an End-to-End, Scalable AI Platform
From data ingestion and embedding generation to model deployment and inference tracking, Databricks offers a one-stop platform to build and scale RAG pipelines, without cobbling together tools.
4. You Need Domain-Specific, Fact-Based Answers
If your LLM must reference internal documentation, product catalogs, technical manuals, or compliance policies, RAG ensures the responses are grounded in truth, not generic or fabricated.
5. You Need Enterprise-Grade Governance and Security
With Unity Catalog, Databricks gives you fine-grained control over access, lineage, and audit trails, essential for industries like retail, manufacturing, healthcare, or financial services.
If you’re building AI applications that rely on your company’s data, Databricks RAG is not just better. It’s essential.
Conclusion
RAG offers a better path forward, enhancing LLMs with access to real-time, domain-specific information. And Databricks elevates that architecture even further by providing an end-to-end, unified platform for ingesting, storing, embedding, retrieving, and governing enterprise data, whether structured or unstructured.
Whether you are building a smart assistant for internal knowledge, powering contextual product recommendations, or delivering instant answers to compliance queries, Databricks RAG Architecture gives you the accuracy, scalability, and control to do it right.
Unlock the Power of Enterprise-Ready Generative AI with Databricks RAG Architecture





Tags: