

Measurable Outcomes
Real results from our Databricks optimization engagements
Databricks Pricing Overview
Databricks uses a usage-based pricing model, which means costs scale with how your teams run clusters, jobs, and workloads, not just with data volume.
Databricks costs come from two main areas:
What increases Databricks costs

Oversized or always-on clusters consume DBUs even when no work is running.

Inefficient Spark jobs extend execution time and drive higher compute usage.

Uncontrolled environments across dev, test, and prod multiply costs silently.
Reduce Databricks Costs. Improve Performance.
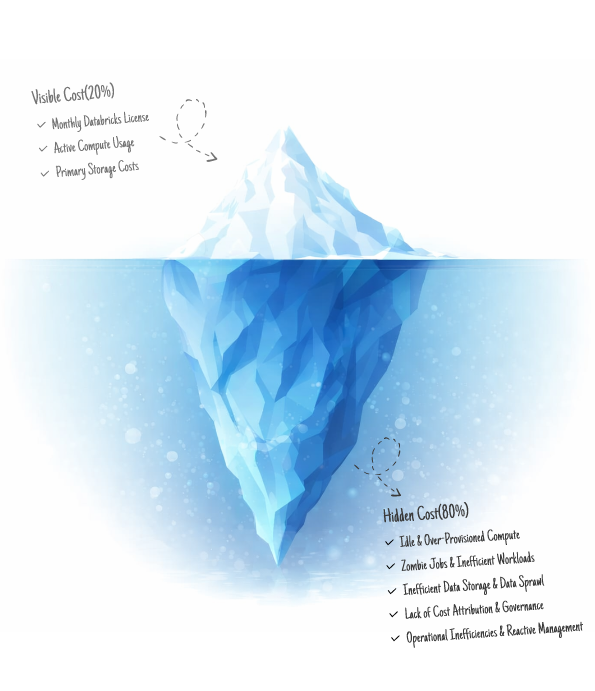
Hidden inefficiencies can quietly inflate Databricks bills as usage scales. Our experts help you identify cost leaks, optimize workloads, and run Databricks more efficiently, without disrupting analytics.
Talk to a Databricks ExpertCostly Mistakes Companies Make
These hidden inefficiencies quietly inflate your Databricks bill every month

Running slow or unoptimized Spark code
Inefficient joins, poor partitioning, and unnecessary data scans increase execution time and drive higher compute consumption.

Leaving “zombie” clusters running
Interactive and development clusters often stay active long after work is done, quietly consuming DBUs and cloud resources.

Oversizing clusters by default
Using large instance types for moderate workloads leads to wasted capacity and inflated costs.

Poor job scheduling and concurrency management
Running too many jobs in parallel or at peak times increases contention and forces teams to scale up compute unnecessarily.

Ignoring data layout and file management
Small files, poor partition strategies, and unmanaged tables slow performance and increase processing costs.

Lack of visibility into workload-level usage
When teams can’t see which jobs or pipelines drive spend, cost issues surface only after the bill arrives.
Best Practices to Optimize Databricks
Proven strategies we implement to reduce costs while maintaining performance

Compute Right-Sizing & Lifecycle Control
We align cluster configurations to actual workload requirements instead of relying on oversized, static setups.
- Right-size instance types and cluster sizes per workload
- Enable auto-scaling with controlled min/max thresholds
- Enforce auto-termination to eliminate idle DBU consumption
- Leverage spot instances for fault-tolerant workloads

Workload Isolation & Scheduling Optimization
We prevent resource contention and unnecessary scale-ups by separating and scheduling workloads intelligently.
- Migrate long-running and scheduled jobs to ephemeral job clusters
- Isolate development, staging, and production workloads
- Stagger high-compute jobs to avoid peak concurrency
- Eliminate redundant pipelines across teams

Spark & Query Performance Optimization
We tune execution at the workload level to reduce runtime and compute usage.
- Optimize joins, partitioning, caching, and file formats
- Apply workload-specific Spark configurations
- Reduce small-file overhead and inefficient data scans
- Enable Photon acceleration where applicable

Storage & Data Layout Efficiency
We improve how data is organized and managed to lower processing overhead.
- Implement Delta Lake best practices for faster reads and writes
- Optimize table layout, partition strategy, and file sizing
- Remove stale or unused data contributing to storage and compute waste

Cost Visibility, Governance & Accountability
We bring transparency to Databricks usage so cost issues are addressed early, not after invoices arrive.
- Implement comprehensive tagging for jobs, users, and teams
- Enable workload-level cost attribution and showback reporting
- Set up usage alerts and anomaly detection
- Establish a regular cost review cadence with stakeholders
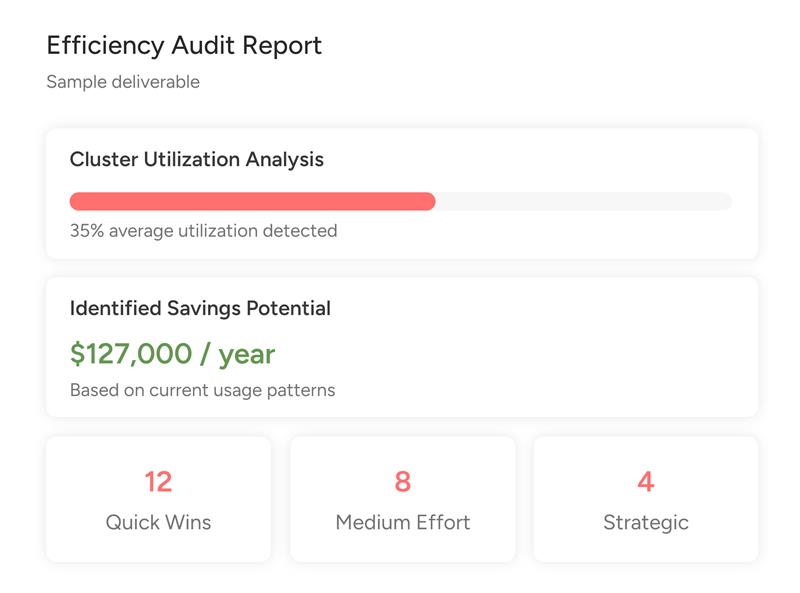
Take the Databricks Efficiency Audit
Uncover hidden cost leaks and optimization opportunities across clusters, jobs, and workloads.
Start the Databricks Efficiency Audit2–3 minutes of assessment. No cost. Reviewed by Databricks certified experts.
How Credencys Helps Optimize Your Databricks Costs
Cost optimization requires more than surface-level tuning. At Credencys, we take a deep, engineering-first approach to help you reduce Databricks spend while improving performance and reliability.
- Lower Databricks costs.
- Faster, more predictable workloads.
- Greater confidence as analytics usage scales across the business.
Assess real usage
We analyze cluster configurations, job execution patterns, and workload behavior to identify where costs are leaking and why.
Optimize workloads at the code and architecture level
Our experts fine-tune Spark jobs, data layouts, and execution strategies to reduce compute time without sacrificing accuracy or speed.
Right-size infrastructure across environments
We help align instance types, cluster sizes, and scaling policies to actual workload needs across dev, test, and production.
Eliminate idle and orphaned resources
From unused clusters to abandoned workflows, we clean up the silent cost drivers that inflate Databricks bills month after month.
Build cost awareness into daily operations
We enable clear visibility into workload-level usage so teams understand how their design and scheduling decisions impact spend.
Success Stories
Global Enterprise (Databricks Cost Optimization)
90%
Cloud computing cost reduction
By overhauling Spark performance, optimizing infrastructure, and applying targeted workload strategies, the client slashed Databricks cloud spend and accelerated critical workflows from 2 hours to 10 minutes.
Read MoreWhy Leading Enterprises Trust Credencys
We combine deep technical expertise with industry knowledge to deliver Data Management services that drive real business value.
Certified Partnerships




Testimonials
Credencys helped us turn fragmented data into a strategic asset. Their team streamlined our architecture and improved data visibility across departments. We’re now making faster, smarter decisions.
Credencys brought structure to our data chaos, enabling better governance and unlocking insights that drive growth.
50+
Enterprise Clients
100%
Certified Consultants
15+
Years Experience
4.9/5
Client Satisfaction
Get Your Free Databricks Efficiency Audit
Our engineering team will analyze your Databricks environment and deliver a comprehensive report with specific, actionable optimization recommendations.
Get Databricks Efficiency AuditEngineering-led assessment. No obligation. No sales pitch.
Frequently Asked Questions
Databricks costs can be estimated by combining expected DBU usage with underlying cloud infrastructure costs. This depends on how long clusters run, the type of workloads executed, and the size and type of instances used. Estimation becomes more accurate when costs are tracked at the job and cluster level instead of at an account level.
Instance type selection has a direct impact on cost and performance. Larger instances increase hourly spend and often remain underutilized if workloads don’t need that capacity. Choosing the right balance of CPU, memory, and storage for each workload helps avoid wasted compute while maintaining performance.
Auto-scaling allows clusters to grow only when workloads demand it and shrink when demand drops. This prevents over-provisioning during low usage periods and reduces the need to size clusters for peak load, helping control costs without slowing down active jobs.
Spot instances offer the same compute capacity at a significantly lower price compared to on-demand instances. When used for fault-tolerant workloads like batch processing or ETL jobs, they can substantially reduce Databricks compute costs while maintaining acceptable reliability.
Right-sizing clusters reduces Databricks costs by matching compute resources to actual workload needs. This avoids paying for unused CPU and memory, lowers DBU consumption, and keeps performance efficient without over-provisioning.
Trusted by Best
Choosing Credencys means partnering with a team that’s deeply committed to unlocking the true value of your data. Here’s why industry leaders trust us:
Our Valued Clientele












Send us a Message
