


Data Mesh vs Data Fabric: Which Data Architecture Fits Your 2026 Data Strategy?
As enterprises accelerate digital transformation, leaders are re-evaluating how data is managed, governed, and scaled across the business. Companies navigating AI, real-time decisioning, and multi-cloud complexity face a critical choice. They must decide whether to decentralize data ownership via domain products or centralize access through a unified layer. The conversation around data fabric vs data mesh has intensified. This is because traditional centralized architectures can’t support modern agility and autonomy demands.
Data fabric architecture and data mesh architecture both have the same goal of offering greater value by dissolving data silos to provide secure access. However, investment, governance, and readiness level may vary in data fabric and data mesh. Analyzing the strategic meaning of data fabric vs data mesh is critical for CIOs, CDOs, and data leaders wanting next-generation data platforms.
Data Engineering Services
Leverage our end-to-end data engineering services to drive business growth and stay ahead of the competition.
What is Data Mesh?
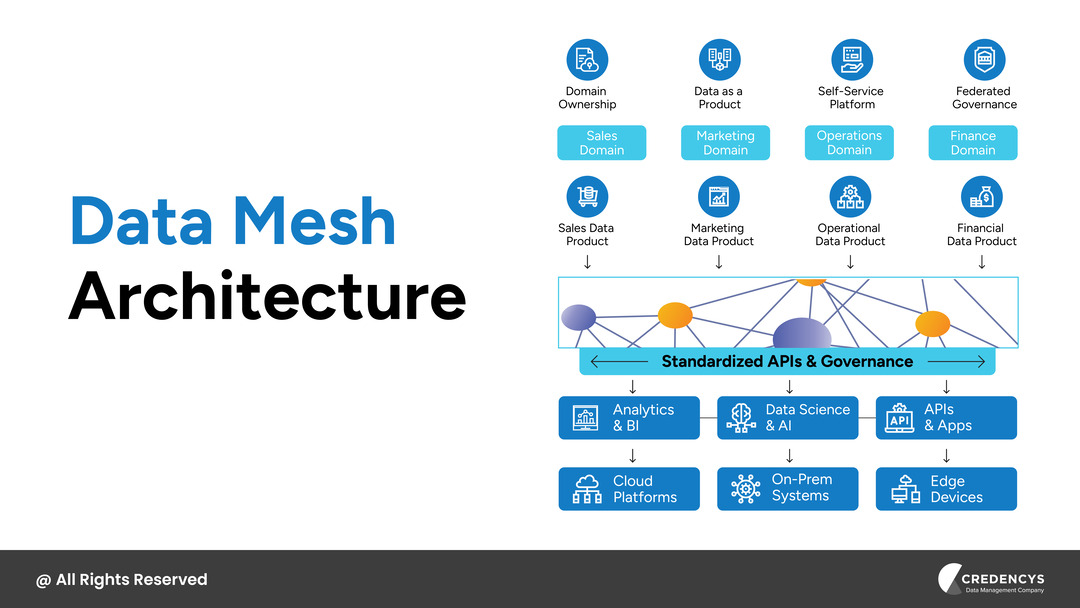
Data mesh is an organizational and architectural approach that treats data as a product owned by domain teams. Data mesh architecture decentralizes data ownership.
Key Principles:
- Domain-oriented ownership – Business or domain teams own, model, and serve their own analytical data products.
- Data as a product – Each dataset has clear SLAs, documentation, and discoverability, just like a software product.
- Self-serve data platform – A shared platform team provides common tooling, standards, and infrastructure for domains.
- Federated governance – Central policies (security, compliance, interoperability) with local autonomy on implementation.
How Data Mesh Works
Data responsibility shifts to business units. For example:
- sales owns sales data
- marketing owns marketing data
- operations owns operational data
Each domain publishes and maintains data products accessible via standards defined centrally.
Data Mesh Architecture
Benefits of Data Mesh
- Reduces bottlenecks of central data engineering teams
- Scales better across large complex organizations
- Improves data quality through domain ownership
- Encourages accountability
What is Data Fabric?
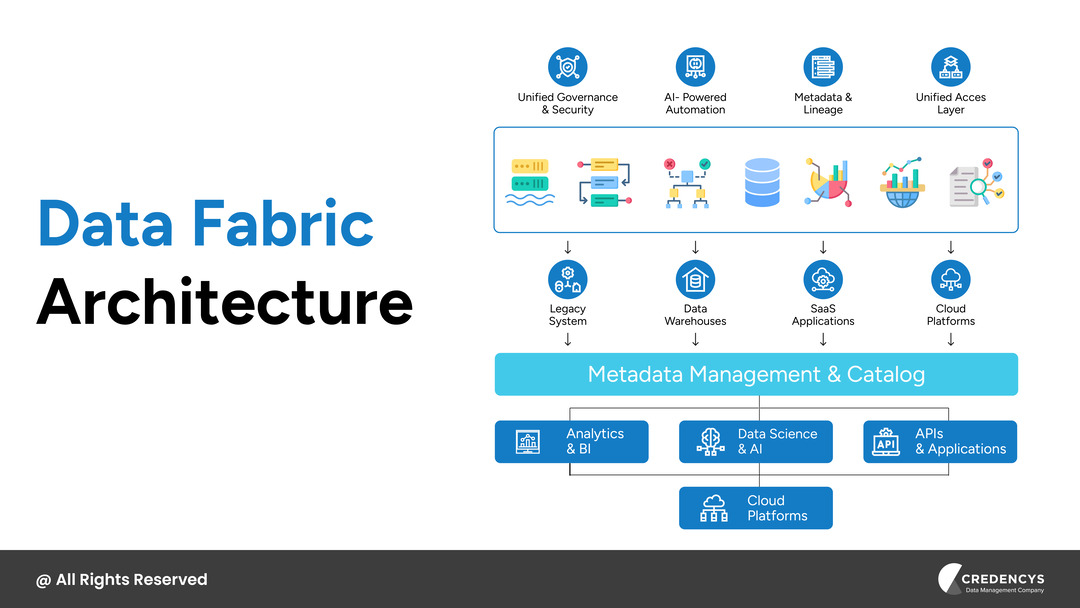
Data fabric is a technology architecture that provides an intelligent layer over distributed data sources. Data fabric architecture is an integrated layer that connects data from on-prem data sources and applications.
How Data Fabric Works
A data fabric creates a “virtualized data layer” so stakeholders access data regardless of where it physically lives. Its core characteristics include:
- Metadata-driven integration – Uses active metadata, catalogs, and knowledge graphs to discover, connect, and orchestrate data.
- Centralized governance layer – Policies for security, privacy, lineage, and quality enforced across sources from a single control plane.
- Virtualized access – Users and systems access data through services or APIs without necessarily moving or copying it.
- Automation and AI – Often uses ML for data classification, quality checks, and policy enforcement.
Data Fabric Architecture
Benefits of Data Fabric
- Centralized governance and security
- Automation reduces manual integration
- Supports hybrid and multi-cloud environments
- Faster time to insights
- Strong metadata management
![]()
![]()
Data Integration Services
Bring data together across platforms to deliver timely insights, improved decision-making, and operational efficiency.
Data Fabric vs Data Mesh: Side-By-Side Architecture Comparison
| Feature | Data fabric architecture | Data mesh architecture |
|---|---|---|
| Governance | Centralized | Federated |
| Design approach | Technology-centric | Organization & domain-centric |
| Ownership | Central data team | Distributed domain teams |
| Scalability | Moderate | High for large organizations |
| Automation | High (AI/metadata driven) | Low–medium |
| Ideal for | Hybrid/multi-cloud integration | Complex distributed teams |
| Primary goal | Seamless data access | Decentralized accountability |
Data Fabric vs Data Mesh: Cost, Complexity & Implementation Comparison
| Criteria | Data fabric | Data mesh |
|---|---|---|
| Primary approach | Centralized, technology-driven unification | Decentralized, domain-driven ownership |
| Cost model | Higher up-front investment in integration, metadata, AI automation | Distributed cost structure; ongoing costs scale per domain |
| Operational cost | Lower long-term cost due to automation & consistency | Higher ongoing cost for governance & domain stewardship |
| Implementation timeline | Faster initial rollout once platforms selected & integrated | Gradual and iterative rollout across domains |
| Complexity type | Mostly technical complexity (integration & virtualization) | Organizational complexity (culture, governance, roles) |
| Required skill sets | Data engineering, platform integration, metadata specialists | Product mindset, governance, decentralization readiness |
| Governance model | Centralized governance that applies consistently across systems | Federated governance shared across domains |
| Data ownership | Data managed centrally through unified architecture | Each domain owns and publishes its own data products |
| Scalability considerations | Efficient for hybrid/multi-cloud and legacy modernization | Scales across distributed teams & business units |
| Ideal use case | Enterprises needing automation & centralized control | Large organizations eliminating central bottlenecks |
| Integration needs | Strong metadata layer & virtualization | Shared standards & self-service platform |
| Risk areas | Vendor lock-in & initial technology complexity | Cultural resistance & inconsistent standards adoption |
| Success indicators | Unified access layer, automated pipelines, policy enforcement | Mature governance, autonomous teams, scalable data products |
Choosing Between Data Fabric and Data Mesh
Choosing an appropriate strategy for data fabric vs data mesh debate will depend on your organization’s current technology stack, data maturity, and operating model. Data fabric architecture design and data mesh architecture design both try to enhance data access and trust, but they solve problems in completely contrasting ways.
Choose Data Fabric if…
A data fabric architecture is well-suited for companies seeking a unified approach to data access, governance, and automation. Choose data fabric when:
- You need unified governance and security
Businesses that collect information from various databases, applications, and cloud systems will find centralized control to be advantageous. Data fabric offers consistent policies on metadata, lineage, encryption, and compliance.
- You rely on both legacy and modern systems
If your organization operates hybrid infrastructure—mainframes, data warehouses, SaaS tools, cloud platforms—a data fabric seamlessly connects everything. It virtualizes data, eliminating the need to migrate all assets to one system.
- You want automation and integration efficiency
Data fabric solutions are based on AI/ML-driven metadata solutions, data catalogs, and orchestration capabilities. This enables data engineers to automatically ingest data, search datasets quickly, and change with minimal SWE effort.
- You prioritize scalability of data applications, not team ownership
If centralization works culturally, and domain autonomy isn’t a priority, data fabric provides the architectural foundation without reassigning ownership.
Choose Data Mesh if…
A data mesh architecture is ideal when organizational scalability matters more than centralized control. Choose data mesh when:
- Your teams or business units work independently
In distributed enterprises, central data teams can’t keep up with demand. Data mesh decentralizes ownership, enabling domain experts to manage their own data products.
- The central platform creates bottlenecks
If a central data engineering team becomes a blocker for analytics requests or onboarding new pipelines, a mesh removes dependency through federated operations.
- You need scalable, decentralized data ownership
Multi-regional, multi-line-of-business organizations benefit from delegating responsibility. Each domain maintains its own data sets, adopts shared standards, and exposes data as discoverable products.
- Cultural readiness favors autonomy
Data mesh requires a transition to product thinking: investing in the governance frameworks, cataloging, and platform tools which give power to the domain teams.
Data Fabric vs Data Mesh: How to Decide
Before adopting either model, ask:
- How diverse are data sources and platforms in our stack?
- Do we need centralized control or distributed accountability?
- Which architecture supports our long-term scalability goals?
- What skills do current teams possess?
Focusing on the technology won’t answer the question. The right choice is to align data fabric and data mesh architecture to people, process, and culture.
Can these approaches work together?
Absolutely. Many enterprises adopt hybrid strategy. Data fabric provides unified metadata and governance, and data mesh empowers domains to self-service the data. The combination of both delivers automation and decentralization. This hybrid model offers flexibility-what modern enterprises need.
Choosing the Right Path Forward
The comparison of data fabric vs. data mesh shows no one size fits all in the best possible implementation framework. Both models have powerful means of breaking down silos and powering better value with data. However, their actual success depends on aligning architecture to business goals, culture, and maturity.
To choose wisely, leaders must assess readiness across people, processes, and platforms, not just technology investment. Modern enterprises increasingly adopt hybrid models—leveraging data fabric as the connective layer while enabling mesh-driven domain ownership—to unlock agility without sacrificing governance.
Ultimately, organizations that make deliberate, strategic decisions around data fabric vs data mesh will be better positioned to adopt trusted data for AI, analytics, and long-term digital advantage. Contact our data engineers to learn more.





Tags: