


Databricks ETL vs Traditional ETL Tools: What’s the Real Difference?
Data is no longer just an operational asset these days, it’s a core driver of innovation, customer experience, and business growth. But as organizations scale and diversify their data sources, traditional ETL (Extract, Transform, Load) tools are struggling to keep up.
Legacy ETL platforms like Informatica, Talend, and Microsoft SSIS were designed for simpler times, when data came in predictable batches, from limited sources, and resided mostly on-premises. Fast forward to now: businesses need real-time insights, AI-ready data, and the flexibility to operate across hybrid and multi-cloud environments.
According to IDC, enterprises will generate over 175 zettabytes of data by 2025 and 90% of it will require real-time processing.
This explosive growth and shift in data velocity have created a critical inflection point for data leaders and business heads:
Should you continue investing in legacy ETL tools, or is it time to embrace a modern, scalable alternative like Databricks?
In this blog, we’ll compare Databricks ETL with traditional tools to help you understand:
- What sets Databricks apart
- How it addresses modern data challenges
- When and why it makes sense to switch
Let’s dive into the real differences that matter for performance, cost, scalability, and long-term business value.
What Are Traditional ETL Tools?
Traditional ETL tools have long been the backbone of enterprise data integration. They were built to extract data from various sources, transform it according to business rules, and load it into centralized systems like data warehouses.
These tools gained popularity for their:
- Graphical interfaces that simplify pipeline design
- Pre-built connectors to popular databases and systems
- Robust scheduling and error-handling features
However, their core architectures were designed in an era when:
- Data volumes were modest
- Batch processing was the norm
- Infrastructure was primarily on-premises
As a result, businesses today face growing challenges when relying solely on these legacy ETL platforms:
- Slow processing speeds for large or streaming datasets
- High licensing and infrastructure costs
- Limited support for unstructured or semi-structured data
- Difficulty scaling across cloud environments
- Lack of flexibility for iterative development and modern data science use cases
While these tools remain effective in some traditional use cases, they often struggle to meet the agility, scale, and real-time demands of today’s data-driven organizations.
What Makes Databricks a Next-Gen ETL Platform?
Databricks reimagines ETL for the modern enterprise by combining the best of big data processing, cloud-native architecture, and AI/ML readiness, all in a unified platform. Here’s what sets Databricks apart from traditional ETL tools:
1. Unified Platform for ETL, BI, and AI
Databricks is more than just an ETL tool. It integrates ETL with:
- Business intelligence (through tools like Power BI and Tableau)
- Advanced analytics and machine learning (with native support for MLflow and notebooks)
This unification breaks down silos and accelerates end-to-end data workflows.
2. Built on Apache Spark for High-Performance Processing
Databricks leverages Apache Spark, a powerful open-source engine to handle massive data volumes with lightning-fast parallel processing. Unlike traditional tools that often struggle with scale, Databricks excels at batch and streaming ETL across terabytes or even petabytes of data.
Ready to Process Data at Scale Without Performance Bottlenecks? Let Databricks do the Heavy Lifting
3. Delta Lake: Reliability Meets Speed
At the heart of Databricks is Delta Lake, an open storage layer that brings ACID transactions, schema enforcement, and time travel to data lakes. This ensures data integrity, easier debugging, and simplified pipeline management, something most traditional tools lack.
4. Cloud-Native and Auto-Scalable
Designed for the cloud from the ground up, Databricks runs seamlessly on AWS, Azure, and Google Cloud. It automatically scales compute resources up or down based on workload, helping businesses reduce costs while maintaining performance.
5. Cost-Effective with Pay-as-You-Use Pricing
Databricks eliminates the need for upfront licenses and maintenance contracts. With a pay-as-you-go model, businesses pay only for the compute and storage they use, leading to better ROI and reduced total cost of ownership.
6. Flexible Development: Code-First and Collaborative
Instead of rigid GUIs, Databricks supports development through notebooks (Python, SQL, Scala), enabling flexible, version-controlled pipelines. Plus, it fosters collaboration between data engineers, scientists, and analysts on the same platform.

In short, Databricks is engineered for agility, scale, and future-proof data operation,s making it a strong contender for enterprises ready to modernize their ETL.
Head-to-Head Comparison: Databricks vs Traditional ETL Tools
To truly understand the shift from traditional ETL to Databricks, let’s compare them across key business and technical dimensions. This comparison helps clarify where traditional tools fall short and where Databricks delivers strategic advantages.
| Category | Traditional ETL Tools | Databricks ETL |
|---|---|---|
| Architecture | Monolithic, often on-prem | Distributed, cloud-native |
| Scalability | Limited, scaling requires hardware expansion | Auto-scaling compute across the cloud |
| Data Processing | Batch-oriented; streaming support is limited or an add-on | Native support for batch and streaming |
| Performance | Slower on large/complex datasets | Optimized via Apache Spark engine |
| Cloud Compatibility | Requires additional setup or cloud connectors | Built for AWS, Azure, and GCP |
| Data Lake Support | Weak or requires external integration | Native Delta Lake integration |
| Schema Handling | Manual and error-prone | Supports schema evolution and enforcement |
| Cost Structure | High upfront licensing + infrastructure costs | Pay-as-you-use; lower TCO over time |
| Maintenance | Manual updates and versioning | Managed service with automatic updates |
| Flexibility | Rigid pipelines, GUI-centric | Flexible pipelines via notebooks and APIs |
| AI/ML Integration | Minimal or external tools required | Native ML/AI tools and collaborative notebooks |
Traditional ETL tools served well in the past, but they were not designed for cloud agility, real-time analytics, or AI-readiness. Databricks offers a future-ready, cost-effective, and scalable ETL alternative that aligns with the demands of modern data ecosystems.
When Should You Consider Switching to Databricks ETL?
Making the move from a legacy ETL tool to a modern platform like Databricks isn’t just about upgrading technology; it’s about enabling speed, agility, and smarter decision-making across the business. Here are clear signs that it’s time to consider the switch:
1. Your Data Volumes Are Rapidly Growing
Traditional ETL pipelines can’t keep up with modern data volumes or the velocity at which data is generated. Databricks handles large-scale, high-speed processing with ease thanks to its distributed architecture and Spark engine.
2. You Want to Reduce ETL Costs
With rising license fees, hardware upgrades, and staffing needs, legacy ETL tools can become expensive to maintain. Databricks’ pay-as-you-use pricing, autoscaling, and minimal infrastructure overhead result in significant TCO savings over time.
3. You are Moving to the Cloud (or Already There)
Legacy tools often require complex integrations to work in cloud environments. Databricks is cloud-native by design, making it a natural fit for AWS, Azure, or GCP ecosystems.
Don’t Let Legacy Tools Slow Down Your Cloud Journey. Move Faster with a Platform Built for the Cloud
4. You are Building AI/ML Capabilities
If your data teams are planning predictive models, recommendation engines, or demand forecasting, Databricks offers end-to-end ML integration, while traditional ETL tools are limited in this area.
5. Pipeline Maintenance Is Slowing You Down
Are you spending more time fixing broken pipelines than creating new ones?Databricks’ modular architecture, notebook-based development, and automated monitoring make pipeline management easier and more reliable.
6. You Need Real-Time or Near-Real-Time Insights
Waiting hours for batch processes to complete? That’s no longer acceptable.
With native support for streaming ETL, Databricks enables real-time dashboards, alerts, and decisions.
7. Your Business Demands Faster Time-to-Insight
Databricks enables faster experimentation, quicker pipeline development, and more agile responses to data needs, a key driver for competitive advantage in fast-moving m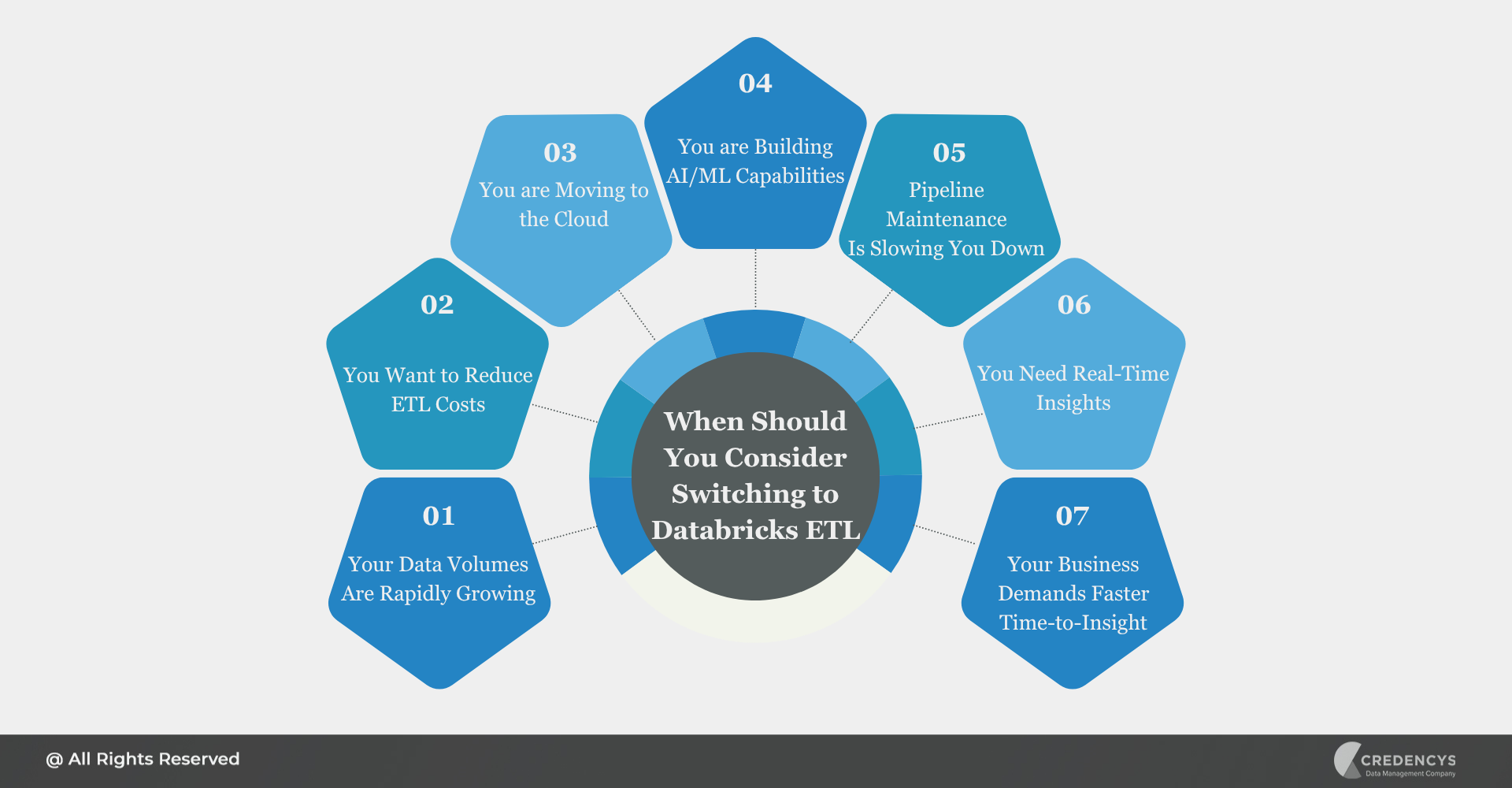
If you recognize even two or three of these signals in your current environment, it’s time to seriously evaluate Databricks ETL.
Why Switching to Databricks ETL Makes Strategic Sense?
For business leaders, modernizing ETL is a strategic move that impacts cost, agility, innovation, and competitiveness. Here’s how you can confidently make the business case for transitioning to Databricks ETL:
1. Lower Total Cost of Ownership
Traditional ETL tools often come with high upfront licensing fees, ongoing maintenance costs, and infrastructure overhead. Databricks eliminates these costs with a usage-based pricing model, allowing you to scale resources dynamically and only pay for what you use, no idle compute or unused capacity.
2. Future-Proof Data Architecture
Investing in Databricks means you are building on a platform that supports batch, streaming, machine learning, and real-time analytics all within a single environment. This reduces the need for multiple tools and future integration headaches, ensuring long-term flexibility and scalability.
3. Faster Time-to-Value
Legacy ETL workflows can take weeks (or months) to develop and deploy. With Databricks, teams can rapidly prototype, test, and launch ETL pipelines using collaborative notebooks and reusable components, accelerating delivery cycles and insights.
4. Strategic Alignment with Business Goals
Whether your focus is customer 360, supply chain visibility, fraud detection, or AI-driven personalization, Databricks gives your teams the tools to deliver faster, aligning technology with measurable business outcomes.
5. Enhanced Governance and Compliance
With features like Unity Catalog, Delta Lake, and built-in lineage tracking, Databricks enables better data governance, auditing, and security, which is critical for regulated industries and growing enterprises.
6. Improved Team Productivity
Databricks fosters collaboration between data engineers, analysts, and scientists on one unified workspace. This breaks down silos, reduces handoff delays, and boosts efficiency, leading to better outcomes faster.
In short, switching to Databricks is an investment in speed, innovation, and sustainable growth.
Choose ETL That Grows with Your Business
As data volumes explode and the pace of decision-making accelerates, clinging to legacy ETL tools can quietly erode your organization’s agility, innovation, and competitiveness. While traditional platforms may still serve basic batch processing needs, they fall short in a world that demands real-time insights, AI-readiness, and cloud-native scale.
Databricks offers a smarter path forward, one that unifies your data engineering, analytics, and machine learning efforts on a single, scalable platform. It’s not just about faster ETL; it’s about enabling a modern data strategy that drives growth, efficiency, and transformation.
If you are serious about future-proofing your data infrastructure and accelerating business value from your data investments, it’s time to re-evaluate your ETL stack and Databricks should be at the top of that list.
Looking to Modernize your ETL Pipelines and Reduce Data Complexity? Credencys Helps Businesses Unlock the Full Potential of Databricks with Tailored Consulting, Implementation, and Support





Tags: