


Data Engineering for AI: Why Clean Pipelines Matter More Than Models
AI has moved from experimentation to execution. Enterprises are using it for forecasting, personalization, fraud detection, predictive maintenance, document search, customer support, and business automation.
Yet many AI initiatives still fail to deliver reliable outcomes. The issue is not always the model.
In many enterprise environments, the problem starts much earlier: fragmented data, inconsistent formats, duplicate records, missing governance, and unreliable pipelines. A powerful AI model cannot create accurate outputs from poor data.
Whether an organization is building machine learning models, generative AI applications, AI agents, or retrieval-augmented generation systems, the quality of the data pipeline directly affects the quality of the result. That is why Data Engineering for AI has become a critical foundation for enterprise AI success.
Before organizations ask which AI model to use, they need to ask a more important question: Is our data ready for AI?
What is Data Engineering for AI?
Data Engineering for AI is the practice of designing, building, and managing data pipelines that prepare enterprise data for artificial intelligence, machine learning, analytics, automation, and generative AI use cases. It goes beyond moving data from one system to another.
Data Engineering for AI focuses on making data clean, connected, contextual, governed, and continuously available for AI systems. It ensures that models, AI applications, and business users receive accurate and trusted data at the right time.
A strong AI data engineering foundation includes data ingestion, integration, cleansing, transformation, quality validation, metadata management, lineage, governance, observability, and continuous feedback loops. Traditional data engineering was often built around reporting and business intelligence.
Data was collected, transformed, and delivered to dashboards for human interpretation. AI changes that requirement.
Why Clean Data Pipelines Matter More Than Models
Many organizations start their AI journey by focusing on model selection. They compare large language models.
They evaluate machine learning frameworks. They look at cloud AI services, automation platforms, and algorithm performance.
These choices matter. But they do not solve the most common AI challenge.
The bigger problem is usually data readiness. A model can only learn from the data it receives.
If the data is incomplete, duplicated, outdated, biased, or poorly governed, the AI output will reflect those weaknesses. Clean data pipelines help AI systems understand the right context.
They ensure that information flows consistently from source systems to AI applications. They reduce manual preparation, improve accuracy, support compliance, and build confidence among business users.
AI models create the intelligence layer. But data pipelines form the foundation on which intelligence depends.
Traditional Data Pipelines vs. AI-Ready Data Pipelines
Not every data pipeline is ready for AI. Many enterprise pipelines were originally designed for reporting.
They collect data from operational systems, transform it, and make it available for dashboards, monthly reports, and business analysis. This approach works well for many analytics use cases.
But AI needs more. For reporting, minor data issues may sometimes be corrected manually.
Business users may notice anomalies, apply filters, or interpret results with context. AI systems do not always have that human layer of correction.
AI-ready data pipelines are built for predictive, generative, and automated use cases. They must support structured, semi-structured, and unstructured data.
They must also continuously provide clean, timely, governed, and contextual data. These pipelines support demand forecasting, churn prediction, product recommendations, fraud detection, predictive maintenance, supplier risk analysis, AI-powered search, and generative AI assistants.
AI-ready pipelines need stronger validation, monitoring, lineage, and governance. They must detect schema changes, data drift, quality degradation, freshness issues, and pipeline failures before they affect AI outputs.
In short, traditional pipelines support visibility. AI-ready pipelines support intelligence.
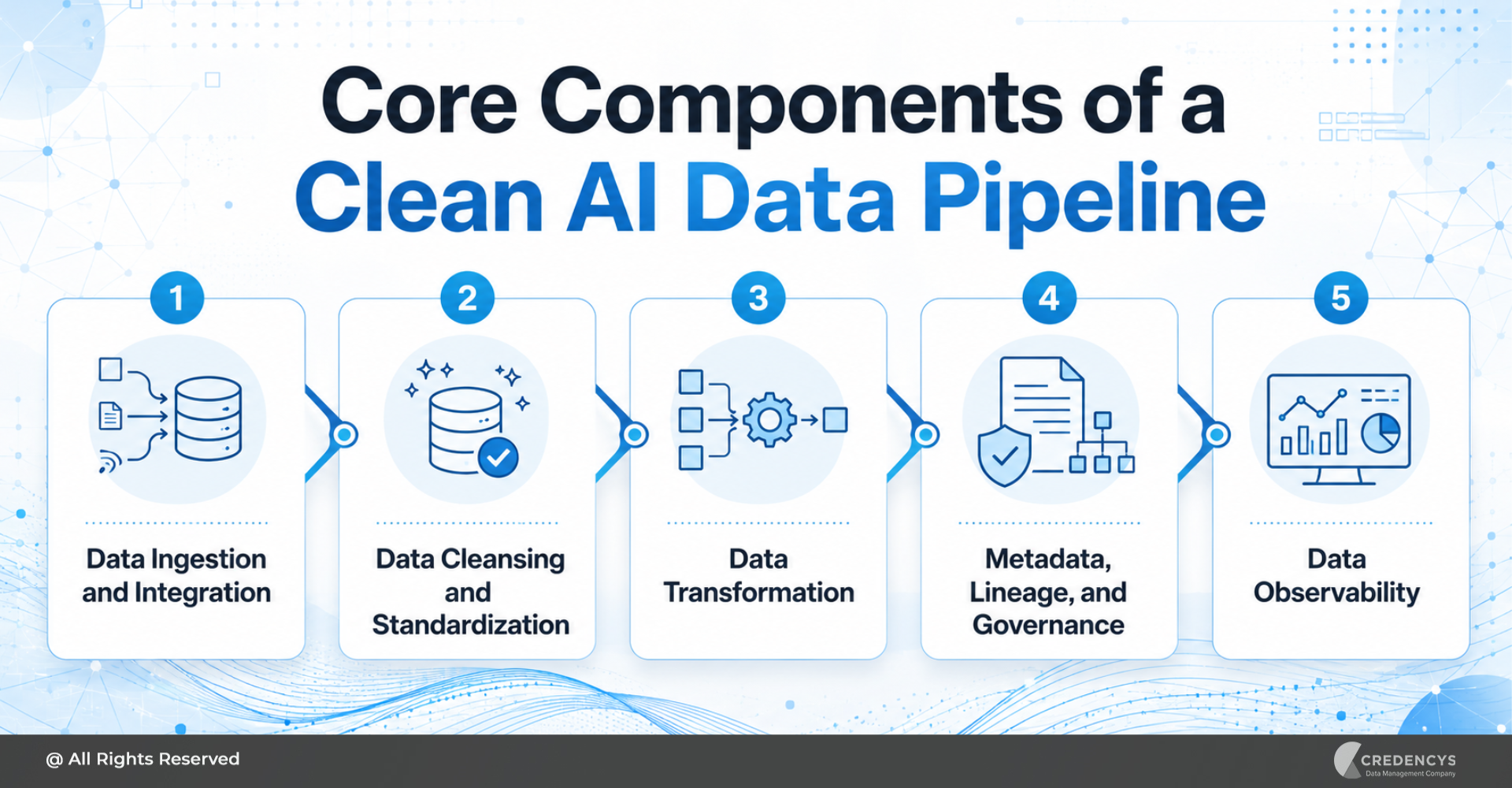
Core Components of a Clean AI Data Pipeline
A clean AI data pipeline is not a single tool or one-time implementation. It is a connected system of processes, platforms, rules, and governance practices that prepare data for AI at scale.
1. Data Ingestion and Integration
Data ingestion collects data from different source systems and brings it into a central environment for processing. For AI use cases, this data may come from ERP systems, CRM platforms, eCommerce platforms, data warehouses, SaaS applications, IoT devices, transaction systems, product information systems, documents, PDFs, knowledge bases, and third-party sources.
Data integration then connects this information to create a unified view. This is especially important for AI because models need business context.
AI performs better when it can understand relationships across business entities.
2. Data Cleansing and Standardization
Raw enterprise data is often messy. Names may be written differently across systems.
Dates may follow different formats. Product categories may not match.
Customer records may be duplicated. Supplier names may be inconsistent.
Units, currencies, addresses, and taxonomies may vary. Data cleansing and standardization fix these issues before the data reaches AI systems.
This may include removing duplicate records, handling missing values, correcting formats, standardizing labels, normalizing units and currencies, aligning taxonomies, matching entities, and validating business rules. Clean data helps AI systems identify reliable patterns.
It also reduces the risk of inaccurate predictions, inconsistent recommendations, and poor decision-making.
3. Data Transformation
Data transformation converts raw data into a format that AI systems can use. This may involve filtering, joining, aggregating, enriching, normalizing, or restructuring data.
It may also include applying business logic so that data reflects how the organization actually operates. Transformation makes data meaningful for AI.
Without it, models may receive technically correct data that lacks business context.
4. Metadata, Lineage, and Governance
AI teams need to know where data comes from, how it changes, and whether it can be trusted. Metadata describes definitions, formats, ownership, source systems, business meaning, and usage.
Lineage shows how data moves through the pipeline, where it originated, how it was transformed, and where it was used. For AI, lineage is critical because enterprises must be able to explain how an output was generated.
If an AI recommendation is incorrect, teams need to trace the issue back to the source. Governance is equally important.
AI systems often use sensitive customer, employee, supplier, financial, and operational data. Without governance, this can create compliance, privacy, and security risks.
Strong governance defines ownership, access controls, privacy rules, consent management, data classification, compliance requirements, and usage policies. For AI, governance is not optional.
It ensures that AI systems use trusted, approved, and responsible data.
5. Data Observability
Even clean pipelines can break. Source systems change.
Data volumes fluctuate. Schemas drift.
Files arrive late. Jobs fail.
Data quality may degrade over time. Data observability helps teams monitor freshness, volume, schema changes, failed jobs, missing values, anomalies, data drift, pipeline delays, and quality rule violations.
This is especially important for AI because small pipeline issues can create large downstream problems. If a model receives stale data or incomplete records, its outputs may become unreliable before anyone notices.
Common Data Pipeline Problems That Hurt AI Performance
AI problems often start as data pipeline problems. When the pipeline is weak, the model receives unreliable inputs.
This leads to poor outputs, low trust, and limited adoption.
Data Silos
Many enterprises store data across disconnected systems. Sales, marketing, finance, operations, supply chain, product, and customer support teams may all use different platforms.
When data stays siloed, AI systems cannot see the complete picture. A customer AI model may miss support history.
A demand forecasting model may miss inventory constraints. A supplier risk model may miss delivery performance or payment history.
Silos reduce context. Reduced context reduces intelligence.
Duplicate Records
Duplicate records are a major issue for AI. If the same customer, supplier, product, or asset exists multiple times across systems, AI outputs become inconsistent.
The model may treat a single real-world entity as several distinct entities. This affects customer segmentation, personalization, forecasting, supplier analysis, product recommendations, and reporting.
Entity resolution, master data management, and data matching help solve this issue by creating trusted records.
Missing, Outdated, or Inconsistent Data
AI systems need complete and current data to identify patterns. Missing customer attributes, incomplete product information, partial transaction history, unavailable operational data, and inconsistent formats can weaken model accuracy.
A product recommendation engine may fail if product attributes are incomplete. A predictive maintenance model may underperform if sensor data has gaps.
A fraud detection model may lose relevance if transaction data is delayed. Data freshness directly affects AI relevance.
Schema drift can create similar issues. If a field is renamed, a new column is added, or a format changes, pipelines may break or silently pass incorrect data to AI systems.
AI-ready pipelines need monitoring to detect these changes before they impact production models.
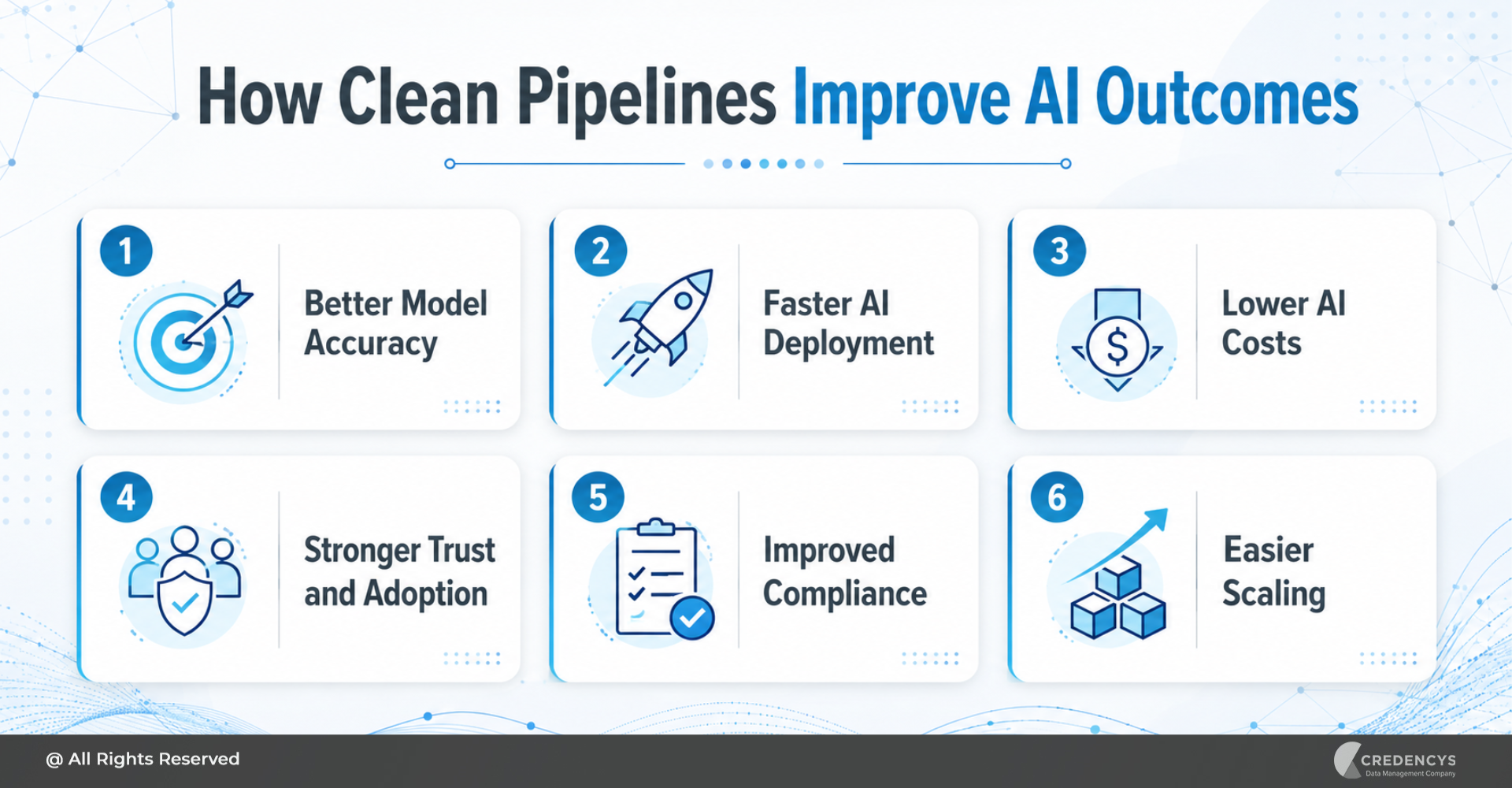
How Clean Pipelines Improve AI Outcomes
Clean AI data pipelines create measurable business value. They help enterprises move from AI experimentation to reliable AI execution.
Here is how clean pipelines improve AI outcomes.
Better Model Accuracy
AI models perform better when they receive accurate, complete, and relevant data. Clean pipelines reduce noise, duplication, missing values, and inconsistencies.
This helps models identify stronger patterns and produce more reliable outputs. Better data leads to better predictions, recommendations, classifications, and generated responses.
Faster AI Deployment
Many AI projects slow down because teams spend too much time manually preparing data. Clean, reusable pipelines reduce repetitive data preparation work.
They make trusted data available faster for model training, testing, deployment, and monitoring. This helps enterprises accelerate AI delivery without compromising quality.
Lower AI Costs
Poor data increases AI costs. Teams spend more time fixing errors, rebuilding datasets, debugging pipelines, retraining models, and explaining unreliable outputs.
Infrastructure costs may also increase when data is duplicated or processed inefficiently. Clean pipelines reduce rework and improve operational efficiency.
Stronger Trust and Adoption
Business users will not adopt AI if they do not trust the outputs. When AI recommendations are inconsistent or inaccurate, users return to manual processes.
Clean pipelines help create more reliable outputs, making it easier for business teams to trust and use AI systems. Trust is essential for adoption.
Improved Compliance
Governed pipelines help enterprises control sensitive data, maintain lineage, manage access, and support audit requirements. This is especially important for industries such as financial services, healthcare, retail, manufacturing, insurance, and logistics, where data privacy and compliance are critical.
Easier Scaling
AI pilots can often run on manually prepared datasets. Enterprise AI cannot. To scale AI across departments, organizations need automated, governed, reusable data pipelines.
Once clean pipelines are in place, enterprises can support multiple AI use cases using the same trusted data foundation. This improves speed, consistency, and scalability.
Building an AI-Ready Data Engineering Strategy
A strong Data Engineering for AI strategy starts with business outcomes, not technology alone. Enterprises need to understand which AI use cases matter, which data is required, and what pipeline capabilities are needed to support those use cases.
Here is a practical approach.
Step 1: Identify High-Value AI Use Cases
Start with clear business problems. Examples include:
- Demand forecasting
- Customer churn prediction
- Fraud detection
- Predictive maintenance
- Product recommendations
- Supplier risk analysis
- Invoice matching
- Customer support automation
- Enterprise knowledge search
- AI-powered personalization
Each use case should have a defined business goal, data requirement, success metric, and owner.
Step 2: Assess Data Readiness
Before building AI models, assess whether the required data is available, accurate, complete, and accessible. Evaluate:
- Data sources
- Data quality
- Data ownership
- Data gaps
- Integration needs
- Governance requirements
- Security constraints
- Current pipeline maturity
This assessment helps identify the work required to make data AI-ready.
Step 3: Modernize Data Architecture
AI-ready data engineering often requires a modern data architecture. Depending on business needs, this may include cloud data warehouses, data lakes, lakehouses, integration platforms, APIs, streaming pipelines, MDM platforms, data catalogs, and vector databases.
The goal is not to add more tools. The goal is to create a scalable and governed data foundation that supports AI, analytics, and business operations.
Step 4: Implement Data Quality Rules
Data quality must be built into the pipeline. Define rules for:
- Accuracy
- Completeness
- Consistency
- Freshness
- Uniqueness
- Validity
- Integrity
These rules should run automatically so that issues are detected before data reaches AI systems.
Step 5: Establish Data Governance
AI needs governed data. Assign data owners.
Define access policies. Classify sensitive data.
Track lineage. Maintain metadata.
Create approval workflows. Document business definitions.
Governance ensures that AI systems use trusted, compliant, and business-approved data.
Step 6: Automate Pipeline Monitoring
AI pipelines need continuous monitoring. Automation helps detect failed jobs, freshness delays, volume changes, schema drift, anomalies, and quality issues.
This reduces manual effort and helps teams fix problems before they affect AI outputs.
Step 7: Create Feedback Loops
AI performance should feed back into the data pipeline. Model outputs, user behavior, business outcomes, and error signals should be captured and used to improve data quality, feature engineering, model performance, and pipeline logic.
This helps AI systems become more accurate and useful over time.
Step 8: Build Reusable Data Products
Instead of creating one-off datasets for every AI project, enterprises should build reusable data products. A data product is a trusted, governed, and reusable dataset designed for specific business needs.
It can support multiple analytics, AI, and operational use cases. Reusable data products help reduce duplication, improve consistency, and accelerate AI scaling.
Why Enterprises Need Data Engineering Before AI Scaling
Many organizations can build AI pilots. Fewer can scale AI successfully.
This happens because pilots often rely on manually prepared datasets, limited source systems, and narrow use cases. The data may be cleaned once for demonstration purposes.
Enterprise AI is different. Enterprise AI needs data to flow continuously from multiple systems.
It needs automated validation, governance, security, observability, and feedback loops. It needs pipelines that can support production use cases across departments.
Without strong data engineering, AI teams spend more time fixing data than improving AI outcomes. AI scaling requires repeatable data foundations.
A company cannot build every AI use case from scratch. It needs clean, reusable pipelines that serve multiple teams and business functions.
AI pilots may run on prepared datasets. But enterprise AI runs on pipelines.
How Credencys Helps Enterprises Build AI-Ready Data Pipelines
Credencys helps enterprises design, modernize, and implement data engineering solutions that prepare data for analytics, AI, machine learning, and generative AI use cases. Our data engineering services help businesses create scalable, governed, and reliable data pipelines across cloud, on-premise, and hybrid environments.
We support enterprises with:
- Data strategy and consulting
- Data pipeline development
- Data integration
- Cloud data platform implementation
- Data engineering modernization
- Data quality management
- Data governance
- Master data management
- Product information management
- AI-ready data architecture
- Analytics and BI enablement
- Generative AI data preparation
Whether an organization is building predictive models, AI assistants, customer intelligence platforms, or enterprise analytics systems, Credencys helps create the trusted data foundation required for reliable outcomes. With strong Data Engineering for AI, enterprises can reduce data chaos, improve AI accuracy, and scale intelligent solutions with confidence.
Conclusion: Better Data Engineering Builds Better AI
The future of AI will not be decided only by who chooses the most advanced model. It will be decided by which organizations can continuously deliver clean, trusted, governed, and contextual data to AI systems.
Models are important. But models depend on data.
If the pipeline is broken, the output will be unreliable. If the data is incomplete, the intelligence will be incomplete.
If the governance is weak, AI risk will increase. Data Engineering for AI helps enterprises build the foundation required for accurate predictions, reliable generative AI, better automation, stronger governance, and scalable AI adoption.
Before investing more in models, enterprises should first strengthen the pipelines behind them. Because better data engineering builds better AI.





Tags: